Problem Definition
I have always been fascinated with the intersection of vision and language, and wanted to find a vision project I could relate to language in some way. Audio-visual speech recognition has been an important research area for many years now, as speech recognition has many applications: audio to text translation, lip reading for the hearing impaired, robot intelligence, etc. However, many high performing results (for letter classification to more complicated tasks such as continuous speech recognition) rely heavily on audio input to accurately classify and detect letters or words. This is because audio can provide very distinctive features such as contributions of friction, aspiration, duration, releases, stops, liquidity, and nasal quality.
For my project, I would like to classify the English alphabet soley using visual information. This could be useful for situations where audio collection is impossible, dangerous, or heavily impaired/noisy. I will be using the AVLetters dataset [9] which contains a total of 10 speakers, each saying the letters a-z three times, totaling 30 videos per letter. Each video is 60 X 80 in resolution, with variable video length. Most videos contain a total of 30-40 frames. The videos are already in grayscale and segmented to the lip portion of the face, which is an easier task than having an entire face in the video or a nosier image frame. However, this is already a difficult task because it will not take audio as input, and will not be user dependent, as there are multiple mouths and a single user is not being learned in the process. This is challenging because people's mouths can have large variety in shape and size, in addition to speaking differently. Note that the dataset I use contains multiple speakers, as opposed to the dataset in [1], which is speaker dependent and only contains one human.
Method and Implementation
My initial goal was to implement the same method as described in the paper [1]. The authors of this paper implemented a very simple method for feature extraction that heavily related to the coursework taught in CS585, so I was excited to use these simple techniques for a seemingly hard task. However, I was unable to obtain results better than random according to their procedure. The paper Extraction of visual features for lipreading follows the following steps:
- Obtain "Motion History Image"
- Calculate 49 Geometric moments, 49 Zernike Moments, or 7 Hu moments
- Use moments as features to be fed into a multi-layer (not deep) neural network for consonant classification
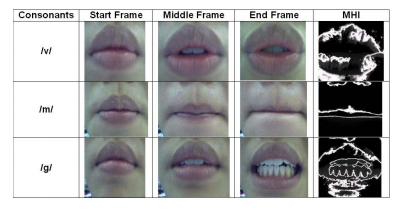
The MHI is defined as the result of successive image differencing amongst binarized versions of the video image frames. The authors also use a "ramp" function, giving greater importance to the more recent frames. The binarization of the grayscale image frames is defined by their handpicked threshold, which they do not state in the paper. There are multiple aspects of this MHI definition that I disagree with. Firstly, I think the binarization of the image frames takes away some useful information around the lips such as cheek and chin movement, which the AVLetters dataset contains as it is not a strick bounding region on the lips. It also appears that the dataset they published with is extremely clean and contains exaggerated movements. This results in much better results than those with a more natural dataset, such as AVLetters. Below in the results section is an example from their dataset which contains extreme lip movements and an even tighter lip segmentation. Their dataset is also smaller than AVLetters, only attempting to classify the consontants, m, g, and v, which are very distinct (m lips meet each other, v teeth meet lower lip, g open mouth closed teeth).
Secondly, I disagree with the use of the ramp function. They multiply each image frames' intensity values by the frame number, suggesting that the later movements are more important in classifiying the letter. However, this again appears to be biased to their curated dataset. I think multiple parts (beginning, middle, and end) of a letter prononciation give information that should aid in the classification of it. Therefore, I didn't use the ramp function.



To use the MHI for classification purposes, we need to have some numerical feature form to feed into a classifying algorithm. While we could use the raw intensity values, i.e. the pixels, the paper suggested three different types of image moments that they tried to use as features. These included geometric moments, zernike moments, and hu moments. I only used Hu moments for the first round of experimentation, and the others are worth looking into. It would also be interesting to see what baseline can be obtained using the raw intensity vectors.
The authors used a mutli-layer neural network with backpropagation weight updates to train a consonant classifier. They shockingly got 100% accuracy with both geometric and zernike moments, and about 96% accuracy with Hu moments. Before using a NN, I wanted to try a multiclass SVM as I am very familiar with them and they do well with smaller datasets.
Current Results + Future Work
To reiterate the desired output: the goal is to take a sequence of image frames (a video), and output the letter being said in the video. In my final results I might label the image with text for its class. I was unable to obtain results significantly better than random even with a binary to small multiclass case (3 letters, for example). With two letters at times I was able to obtain 53-54% accuracy, but still, this is very very low relative to what the paper suggests. I primarily think this is due to the quality of my feature representations, as the final shapes resulting from the MHI are much weaker compared to those shown in the paper. I would like to spend more time refining the image differencing process to try to extract better shape representations before computing any image moments. I will also try the geometric and zernike moments in addition to the Hu. I can also try using a NN now that I have used an SVM.
If I am unable to improve results with the small tweaks mentioned above, I will try to implement several more techniques published in sources [2] - [8]. Below is an example from the very clean, exaggerated dataset presented in [1], which is noteably easier to work with than the dataset I am choosing to, again cited in [9].
Results | |||
| EX 1 | EX 2 | EX 3 | |
| Original Video Frames |  |
 |
 |
| Image Differences |  |
 |
 |
Note: The video frames and frame differences do not align, they are just more clear examples of each shown for visual example of the mentioned methods. I have concatenated an example set of image frames: below shows one participant saying the vowel o.
Credits and Bibliography
[1] Visual Speech Recognition Using Image Moments and Multiresolution Wavelet Images
[2] “EIGENLIPS” for Robust Speech Recogition
[3] Audio-Visual Speech Modeling for Continuous Speech Recognition
[4] A Coupled HMM for Audio-Visual Speech Recognition
[6] Deep Audio-Visual Speech Recognition
[7] Design Issues for a Digital Audio-Visual Integrated Database
[8] Building a Data Corpus for Audio-Visual Speech Recognition