Learning to Separate: Detecting Heavily Occluded Object in Urban Scenes

While visual object detection with deep learning has received much attention in the past decade, cases when heavy intra-class occlusions occur have not been studied thoroughly. In this work, we propose a novel Semantics-Geometry Non-Maximum-Suppression (SG-NMS) algorithm that dramatically improves the detection recall while maintaining high precision in the complex urban scenes with heavy occlusions. Our SG-NMS is derived from a novel embedding mechanism, in which the semantic and geometric features of the detected boxes are jointly exploited. The embedding makes it possible to determine whether two heavily-overlapping boxes belong to the same object in the physical world. Our approach is particularly useful for car detection and pedestrian detection in urban scenes where occlusions often happen. We show the effectiveness of our approach by creating a model called SG-Det (short for Semantics and Geometry Detection) and testing SG-Det on two widely-adopted datasets, KITTI and CityPersons for which it achieves state-of-the-art performance.
SG-Embedding
Our key idea for separating occluded objects in an image is to map each putative detection to a point in a latent space. In this latent space, detections belonging to the same physical object form a tight cluster; detections that are nearby in the image plane, but belong to different physical objects, are pushed far apart. The compuation of SG-Embedding is described in our paper.
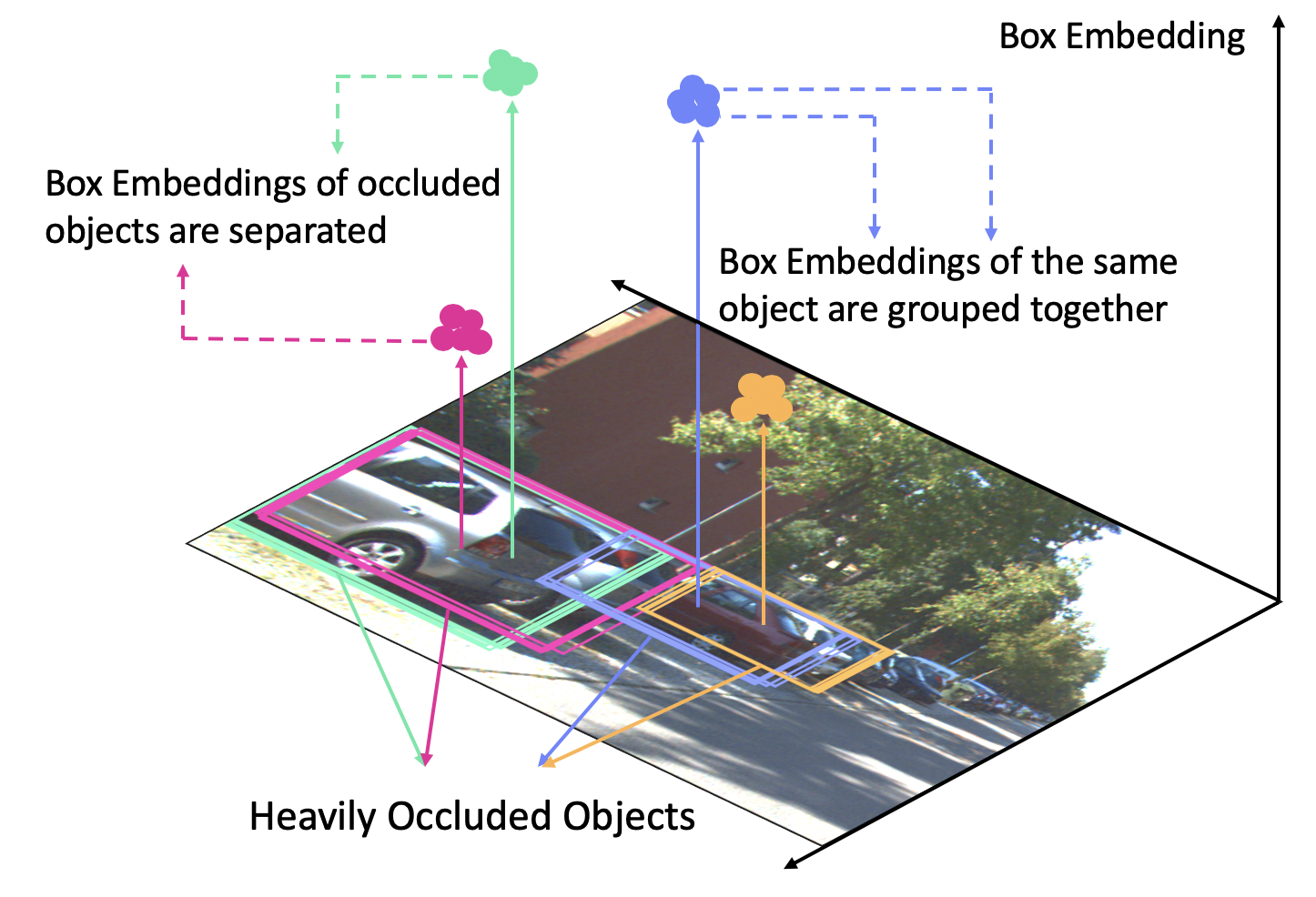
SG-NMS
SG-NMS first selects the box with the highest detection score as the pivot box. For each of the remaining boxes, its IoU with the pivot box is denoted by $\tau$, and the box will be kept if the $\tau < N_t$. When $\tau > N_t$ , SG-NMS checks the distance between its SGE and the SGEof the pivot box. If the distance is larger than $\Phi(\tau)$, the box will also be kept. Here $\Phi(\cdot)$ is a monotonically increasing function, which means that, as $\tau$ increases, a larger distance is required to keep it.

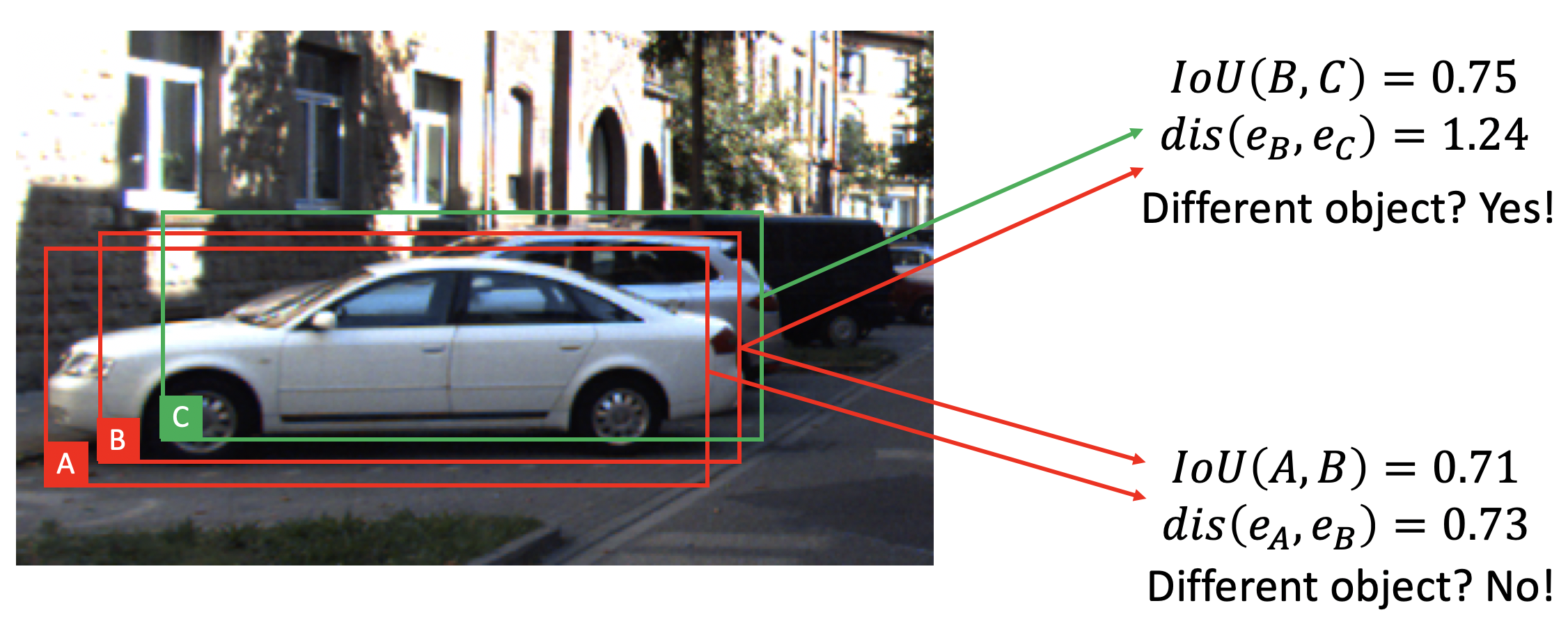
Intuitively, the SG-NMS compare not only the IoU between boxes but also whether they belong to the same object (indicated by the SG-Embedding distance)In the following example, although box B and C shares a large IoU, the distance between their SG-Embedding is large, and they belong to different objects and will not suppress each other. However, box A and B have a large IoU and their SG-Embedding distance is small, so they belongs to the same object and the SG-NMS would suppress one of them whoever has the lower detection score.
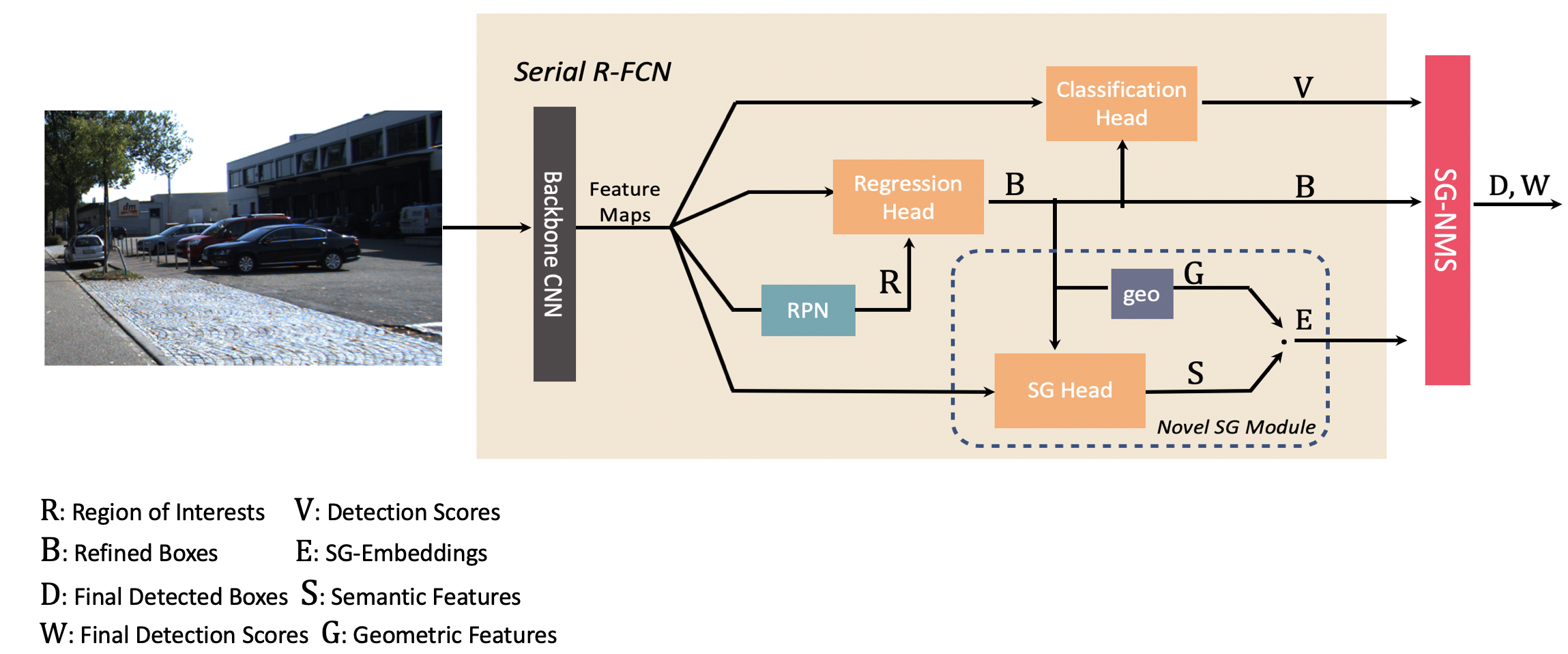
Serial R-FCN
In order to compute SGEs that can capture the difference between geometric features of boxes belonging to different objects, we need to align extracted semantic features strictly with the refined boxes after bounding box regression. However, this cannot be achieved by normal two-stage CNN-based object detectors where the pooled feature is aligned with the RoI instead of the refined box because of the bounding-box regression.
To address this problem, we propose Serial R-FCN. In Serial R-FCN, the classification head along with the SG module is placed after the classagnostic bounding box regression head; thus, the whole pipeline becomes a serial structure. The classification head and the SG module use the refined boxes for feature extraction rather than the RoIs. Thus, the pooled features are strictly aligned with the refined boxes.
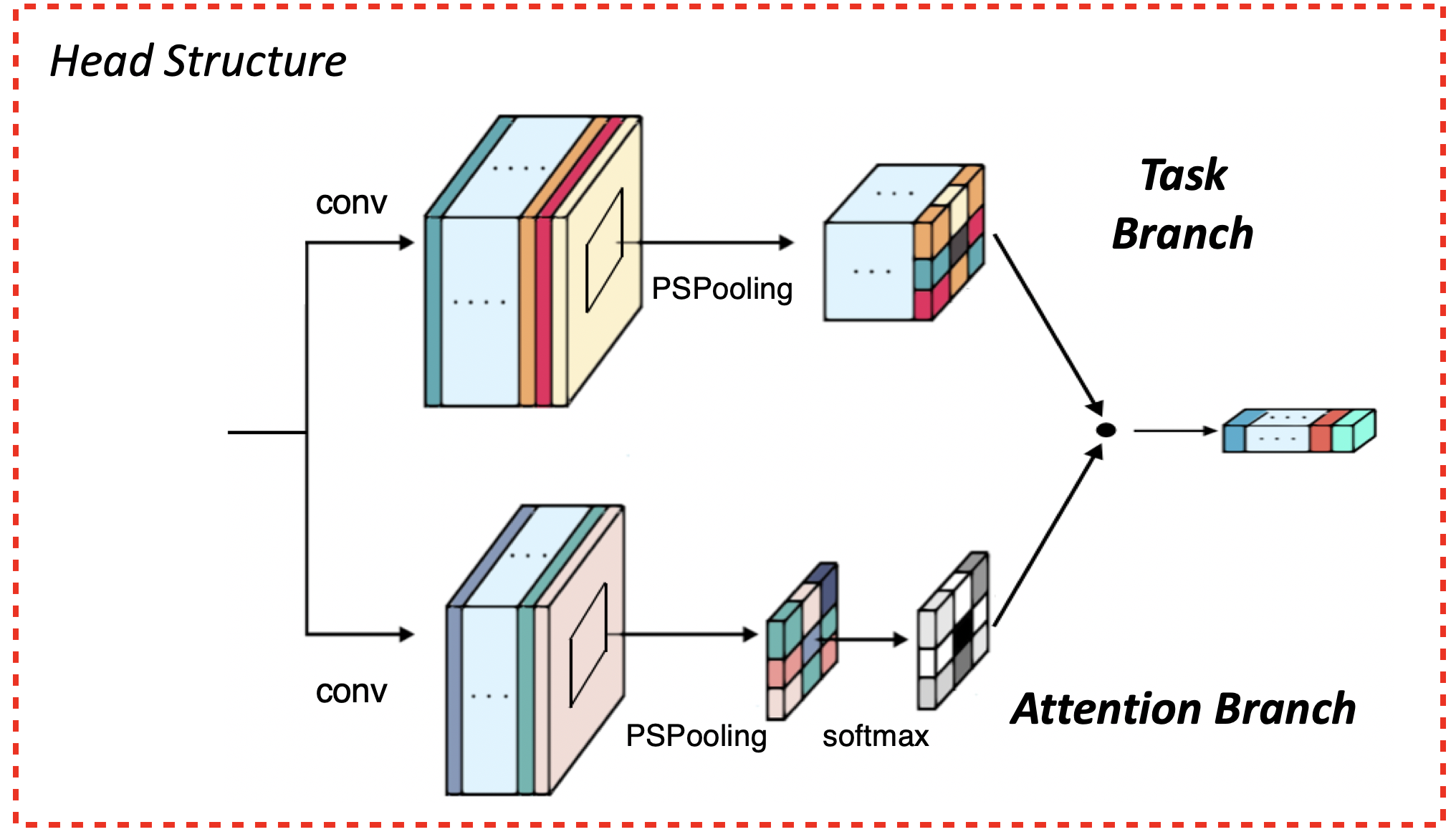
All heads share a similar architecture. The feature map computed by the backbone network is processed by two branches to yield two score maps. Then a Position Sensitive RoI-Pooling is applied to produce two grids of $k^2$ position-sensitive scores – a task-specific score and an attention score. A softmax operation transforms the attention score into a discrete distribution over the $k^2$ grids. Finally the $k^2$ task scores are aggregated by the attention distribution to yield the final output scores.
Visual Results
Comparison with other NMS algorithms on KITTI

More Results on KITTI

Demo Video on KITTI
Comparison with other NMS algorithms on CityPersons


More results on CityPersons
