CS 112 Lab 8: Hash functions
Agenda
Why good hash functions?In today's lab, we will look at creating hash functions. An hash function takes a data object as input and returns an integer index to a hash table bin, the bin index is computed as a function of the input data. The number of hash buckets is typically fewer than the number of data objects causing collisions, most bins will contain more than one data object. A good hash function is essential to distribute data uniformly among the bins to gaurantee search performance. A badly designed hash function tends to clump data into a few bins. Since a linear search among objects in a bin is used to find a match, the search performance is drastically affected. The choice of a good hash funciton depends on the objects being stored and their distribution. The histograms below show bin distributions for a simple hash function. Names of U.S. counties (e.g., "Washington County, Alabama") are used as objects to populate the hash table. The hash function in our example returns ascii value of the first character in the county name modulo the number of hash bins as the bin index. In the first figure, we choose 26 bins. The histogram hence refects the distribution of county names starting with different letters of the alphabet. In the second figure with 65 bins, clumping of data is more apparent. The given hash function is clearly a poor choice for this dataset. Your goal for this lab is to come up with a better hash function to more uniformly distribute the data.
A poor choice of hash function yields more counties clumped into few bins |
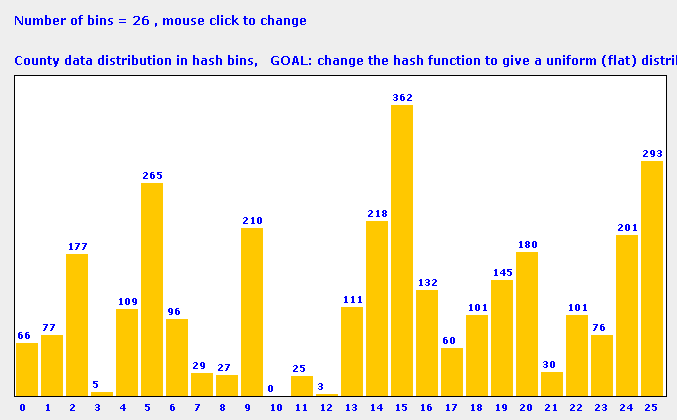
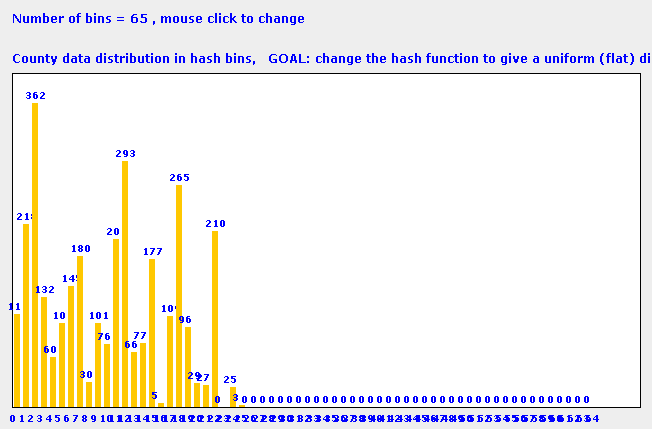
Today's example and associated tasks
|
Download class files for the lab below,
|
Solutions
|
URL
http://cs-people.bu.edu/tvashwin/cs112_spring08/lab08.html |