|
Wenda Qin BioI am Wenda Qin, a PhD candidate in Computer Science at Boston University (BU), advised by Professor Margrit Betke and co-advised by Professor Derry Wijaya. My research centers on multimodal learning, with a focus on integrating Computer Vision (CV) and Natural Language Processing (NLP), enabling improved performance on specialized multimodal systems. Education. I earned my Bachelor of Engineering (B.E.) in Software Engineering from South China University of Technology in 2016 and my Master of Science in Computer Science (M.Sc.) from Boston University in 2018. Since then, I have been pursuing my Ph.D. in Computer Science at Boston University. Internship. I worked in Honda Research Institute as a research intern at 2021 for a vision-and-language navigation project. And I worked in Xmotors.ai as a research intern at 2022 for a 3D captioning project. Conference Paper Reviewer. I also served as a invited conference paper reviewer for CVPR’22, ’23,’24, ECCV’22, ’24, and ICCV’23. Teaching. Besides research, I worked as a TF for multiple courses in BU over the last 6 years, including AI, NLP and computer graphics. |

|
ResearchMy research spans multiple domains within Computer Vision (CV) and Natural Language Processing (NLP), targeted on specialized systems. This includes work in document analysis, ear recognition, scene text recognition, and vision-and-language navigation. Through these projects, I have gained extensive experience with a variety of machine learning, CV, and NLP models, ranging from traditional methods like Support Vector Machines (SVMs), Faster R-CNN, to cutting-edge large language models such as LLaMA 3. |
|
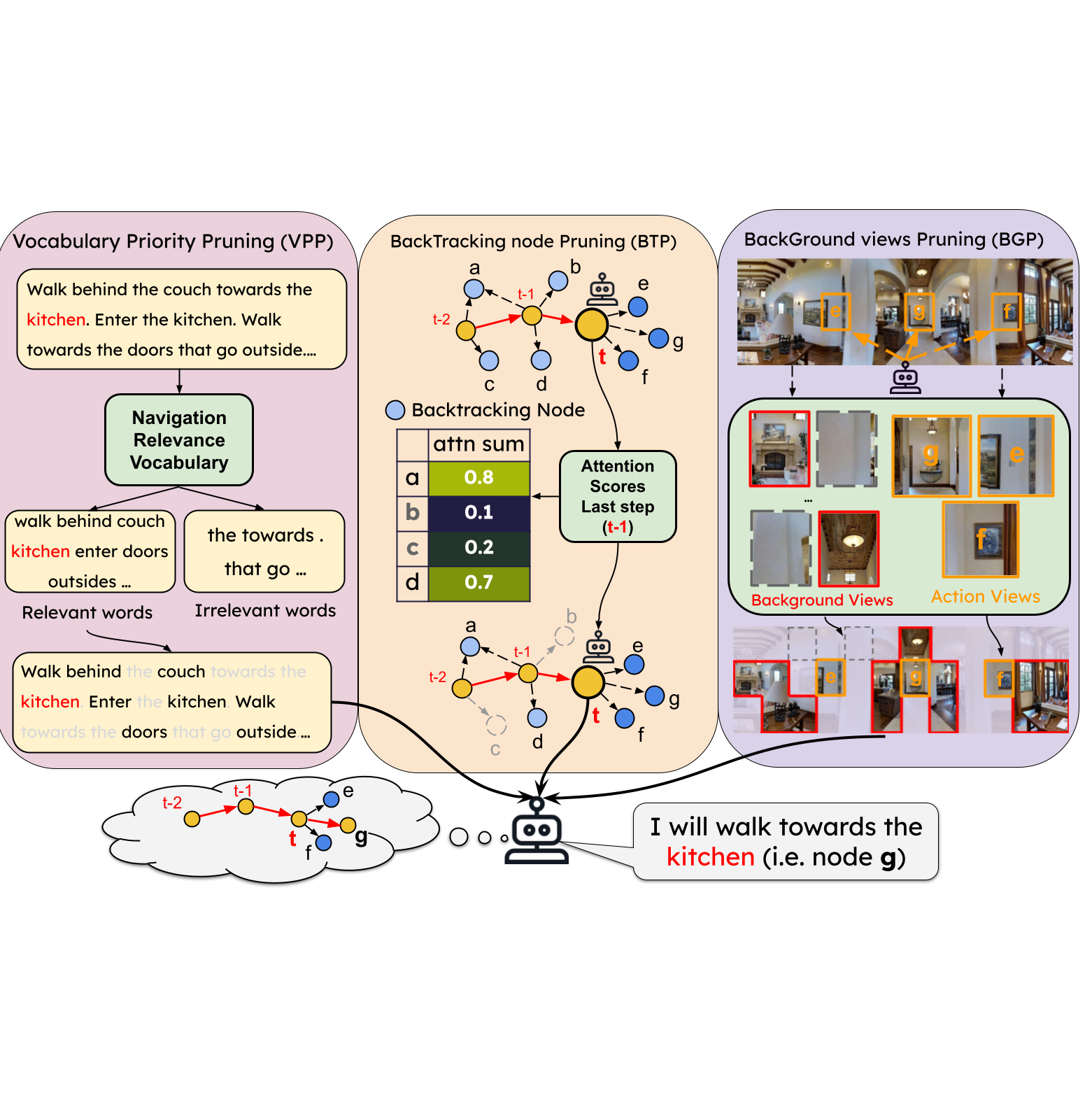
Read and Walk Less: Improving the Efficiency of Vision-and-Language Navigation via Finetuning-Free Textual, Visual, and Topological Token Pruning
Wenda Qin, Andrea Burns, Bryan A. Plummer, and Margrit Betke, in progress. We introduce a hybrid pruning framework that leverages a Large Language Model (LLM) to identify and prioritize the pruning of irrelevant word tokens while combining BackTracking node Pruning (BTP) and BackGround view Pruning (BGP). This approach preserves essential navigation guidance, improves path and input efficiency, and significantly enhances inference efficiency under high pruning rates, all while maintaining success rates comparable to baseline methods. |
|
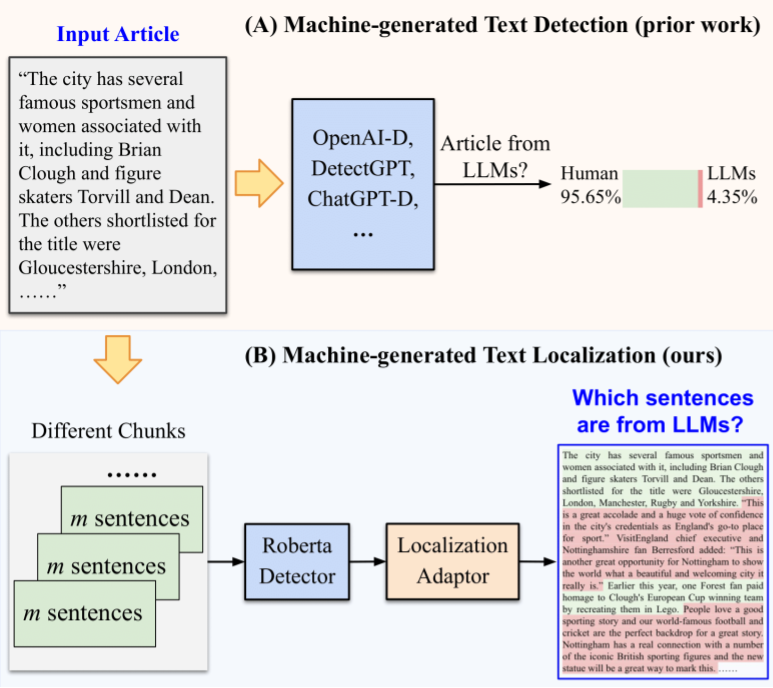
Machine-generated Text Localization
Zhongping Zhang, Wenda Qin, and Bryan A. Plummer, Findings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2024 Github We introduce a data creation pipeline to generate articles containing both human-written and machine-generated text, enabling automated training and evaluation data generation for the MGT localization task. To address challenges in accurately localizing short machine-generated texts, we employ a majority vote strategy with overlapping predictions in our AdaLoc approach, providing dense sentence-level labels for articles. |
|
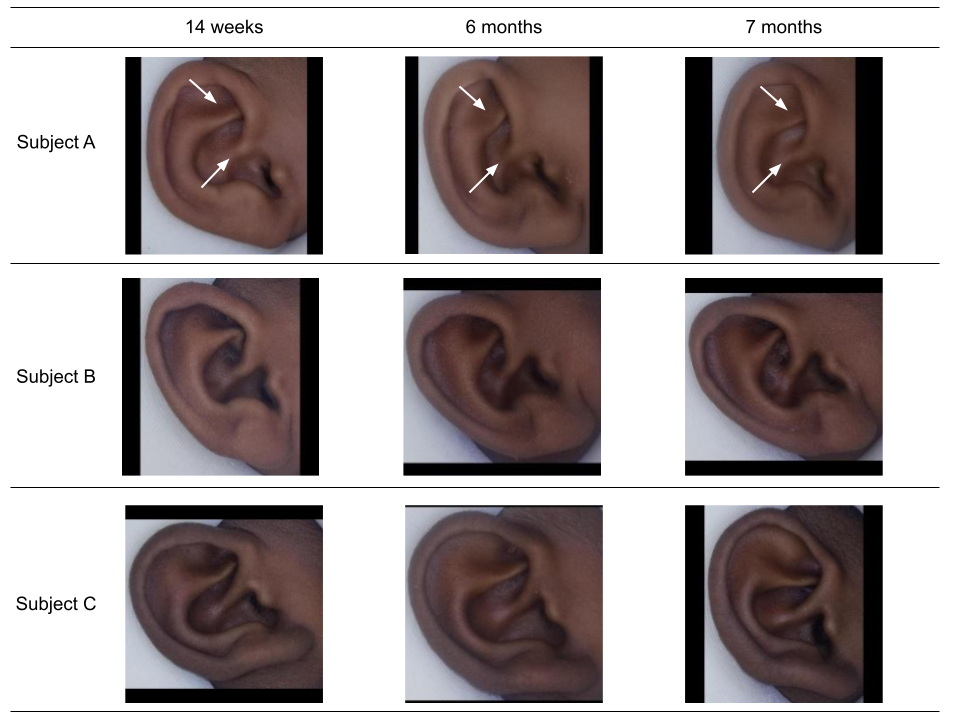
Age-constrained Ear Recognition: The EICZA Dataset and SASE Baseline Model
Wenda Qin, Lauren Etter, Alinani Simukanga, Christopher J Gill, and Margrit Betke IEEE International Joint Conference on Biometrics (IJCB), 2023, Best Poster. Github We curated the EICZA dataset, comprising ear images from infant participants in Lusaka, Zambia, taken at various ages. We introduced the age-constrained ear recognition task, where models identify individuals despite age-related changes, and found that existing models struggled with this challenge. To address this, we developed the SASE model, which utilizes a Transformer encoder to process sequences of ear images across different ages, significantly improving recognition accuracy in age-constrained scenarios. |

|
LAL: Linguistically Aware Learning for Scene Text Recognition
Yi Zheng, Wenda Qin, Derry Wijaya, and Margrit Betke the 28th ACM International Conference on Multimedia (ACM-MM), 2020. We developed the scene text recognition model LAL, which combines image and language information through a novel multi-network approach, leveraging word-analysis techniques from NLP to address a computer vision recognition task. Building on this, we created the LAL* text spotting system by integrating LAL with an existing text detector, achieving robust performance on widely used benchmarks.
|
|
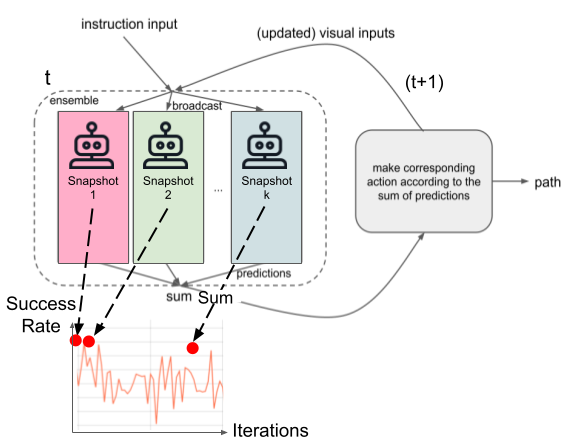
Explore the Potential Performance of Vision-and-language Navigation Model: a Snapshot Ensemble Method
Wenda Qin, Teruhisa Misu, and Derry Wijaya arXiv preprint, 2021. We discovered that the best snapshots of the same VLN model behave differently while having similar navigation success rates. Based on this observation, we propose a snapshot ensemble method to take advantage of the different snapshots. We also propose a past-action-aware modification on the current best VLN model: the RecBERT. It creates additional variant snapshots to the original model with equivalent navigation performance. The ensemble reached the state-of-the-art performance over diverse navigation datasets.
|

|
Extracting Text from Scanned Arabic Books: a Large-scale Benchmark Dataset and a Fine-tuned Faster-R-CNN Model
Randa Elanwar, Wenda Qin, Margrit Betke, and Derry Wijaya International Journal on Document Analysis and Recognition (IJDAR), 2021. Github We created the 9000+ dataset BE-Arabic-9K by scanning pages from Arabic books with a wide variety of layout shapes and content and publicly sharing it. We annotated and releasing a subset of 1500 images for physical layout analysis research purposes. We presented a deep learning baseline model FFRA based on fine-tuning pre-trained Faster-R-CNN structure for page segmentation.
|

|
Text and Metadata Extraction from Scanned Arabic Documents using Support Vector Machines
Wenda Qin, Randa Elanwar, and Margrit Betke Journal of Information Science, 2022. We proposed LABA, a system based on multiple support vector machines to perform logical Layout Analysis of scanned Books pages in Arabic. The system detects the function of a text region based on the analysis of various images features and a voting mechanism.
|
|
This webpage is modified from the template provided by Jon Barron. |