Overview
Physical layout analysis (PLA) of a scanned document is the ability to segment the layout of the document image and identifying the class to which each image region belongs without using text recognizers or human supervision. Successful physical layout analysis leads to better performance of text recognizers and other applications like search and retrieval, word spotting, PDF-to-Word conversion, etc.
Scientific solutions devoted to physical layout analysis of Arabic documents are few and difficult to assess because of differences in methods, data, and evaluation metrics. Researchers cannot compare their work to the work of others due to the absence of publicly available research datasets that are suitably annotated for evaluating solutions to physical layout analysis tasks.
This competition will provide: (1) a benchmarking dataset for testing physical layout analysis solutions, which contains an annotated test set of scanned Arabic book page samples with a wide variety of content and appearance, and (2) a full evaluation scheme by offering code to compute a set of evaluation metrics to both analysis tasks (segmentation and classification) for quantitative evaluation, and to visually asses the analysis result for qualitative evaluation.
Tasks and Procedures
Task is to provide zone-level segmentation results to the benchmarking data: i.e. BB coordinates of each zone in addition to identifying the zone type for being “text” or “non-text”.
The zone segmentation evaluation should be performed based on certain metrics defined by Shafait et al. [1]: Average black pixel rate, over-segmentation error, under-segmentation error, correct-segmentation, missed-segmentation error, false alarm error, overall block error rate.
The zone classification evaluation should be performed based on: Precision (Pr), Recall (Rec), F1-measure (F1) and Average class accuracy (Acc) on both pixel and block levels
Who can register
- New systems (not previously published) are invited to participate by submitting a 6-pages draft to ASAR 2018 workshop describing the system and results on private data beside the competition benchmarking data.
- Published systems are welcomed to participate with a technical report including full system description and results on the competition benchmarking data
- Note:Registration is important even if you are not going to participate in the challenge. Having your contact information will help us keep you updated with future events and resources of your interest.
- Note: Participants are allowed to submit results of more than one system
After registration:
- Down load data: Benchmarking data with annotations could be downloaded here
- Evaluate your system: Code to compute segmentation and classification performance on the benchmarking data could be downloaded here
- Submit draft/report: New drafts and technical reports should be submitted to ASAR2018 for review here.
Please make sure you are choosing the right competition topic (C1) while submitting your paper via easychair. Accepted papers will be added in a special section of the ASAR 2018 proceedings. Results will be published in the ASAR-2018 workshop in London, United Kingdom.
- Submit a camera ready version: Resubmission of a final version of the accepted new systems after performing the required modifications (if any)
- Register to ASAR2018: Attending the workshop for presentation and announcement the results
Resources and submissions
BCE-Arabic benchmarking dataset[2]
- This dataset is composed of scanned pages from different Arabic books with both normal (V1) and complex (V2) layouts. BCE-Arabic V1 is publicly available since 2016 on Boston University's website, while V2 is not yet uploaded.
- BCE-Arabic comprises variety of page content and was collected from over 700 books from different publishers with a variety of layout problems (decorative backgrounds, different printing technologies, low quality paper effects, etc.)
- The benchmarking dataset currently contains 90 images in 3 equal sets according to the layout content. The 90 images contain 927 text zones, 149 image zones, and 36 graphics/decorations zones (Total of 1112 zones):
- Set A: 30 images of single column normal layouts (297 text blocks, 53 image blocks)
- Set B: 30 images of double column simple layouts (379 text blocks, 54 image blocks, 19 graphics blocks)
- Set C: 30 images of complex layouts (251 text blocks, 42 image blocks, 17 graphics blocks)
Annotations are performed using Alethia tool [3], providing annotations in PAGE xml format [4]. The evaluation procedure is not blind. The benchmarking dataset should be sent to participants after the registration date is due.
The evaluation code:
- The evaluation code helps participants to evaluate their analysis (segmenation + classification) result. Pseudo Code of evaluation steps here. Note: When submitting the benchmarking result, It is important to provide visual representation of results especially error cases associated with analysis.
- The code is written in C++, with Visual Studio 2013 and OpenCV 3.1. It's a .exe file which accepts one image and its related files (as input) at a time.
- The evaluation code takes the original image, its processed result and ground truth (in PAGE format) as input. The processed result should be contours indicated by multiple vertices which is segmented by your designed algorithms in addition to classification result. Here's an example of input files of our evaluation code.
- The output of the evaluation code is an xml file contains evaluation stats. Here's an example of output xml file
- If you have any difficulty when using the evaluation code, please contact wdqin@bu.edu
Segmentation evaluation metrics:(Detailed computation in Pseudo Code here)
- The average black pixel rate (AvgBPR) represents the number of black pixels contained in segmented blocks compared to the corresponding blocks in the ground truth image.
- The over-segmentation error (OSE) compares the number of over-segmented blocks to the number of ground truth blocks.
- The under-segmentation error (USE) compares the number of under-segmented blocks to the number of ground truth blocks.
- The correct-segmentation (CS) metric compares the number of correctly segmented blocks to the number of ground truth blocks.
- The missed-segmentation error (MSE) compares the number of missed segments to the total number of ground truth blocks.
- The false alarm error (FA) compares the number of false alarms to the total number of ground truth blocks. (Happens in case of border noise presence)
- The overall block error rate ρ combines OSE, MSE, and USE and compares the result to the total number of ground truth blocks.
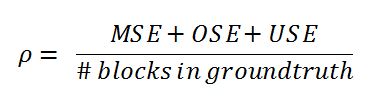
Classification evaluation metrics:
- The following metrics will be used: Precision (Pr), Recall (Rec), F1-measure (F1) and Average class accuracy (Acc) on both pixel and block levels.
Contact Info
This competition will be organized members of a joint team from Boston University USA, and Electronics Research Institute, Egypt:
- Randa Elanwar, Researcher, ERI (randa.elanwar@eri.sci.eg): for queries and suggestions
- Margrit Betke, Professor BU (betke@bu.edu)
- Rana S.M. Saad, Research assistant ERI (rana@eri.sci.eg): for questions or problems with annotations.
- Wenda Qin, M.S student BU (wdqin@bu.edu): for questions or problems with competition web page.
References
- [1] F. Shafait, D. Keysers, and T.M. Breuel. Performance evaluation and benchmarking of six-page segmentation algorithms. IEEE Transactions on Pattern Analysis and Machine Intelligence, 30(6), pp. 941-954, 2008
- [2] R. S. M. Saad, R. I. Elanwar, N. S. Abdel Kader, S. Mashali, and M. Betke. BCE-Arabic-v1 dataset: A step towards interpreting Arabic document images for people with visual impairments. In ACM 9th Annual International Conference on Pervasive Technologies Related to Assistive Environments (PETRA'16), pp. 25-32, Corfu, Greece, June 2016.
- [3] C. Clausner, S. Pletschacher, and A. Antonacopoulos. Aletheia - an advanced document layout and text ground-truthing system for production environments. IEEE International Conference on Document Analysis and Recognition (ICDAR), pp. 48-52, Sept. 2011.
- [4] S. Pletschacher and A. Antonacopoulos. The PAGE (Page Analysis and Ground-Truth Elements) format framework. In 20th International Conference on Pattern Recognition (ICPR), pp. 257-260, 2010.

