

There's a lot of excellent work that also evalutes compositionality.
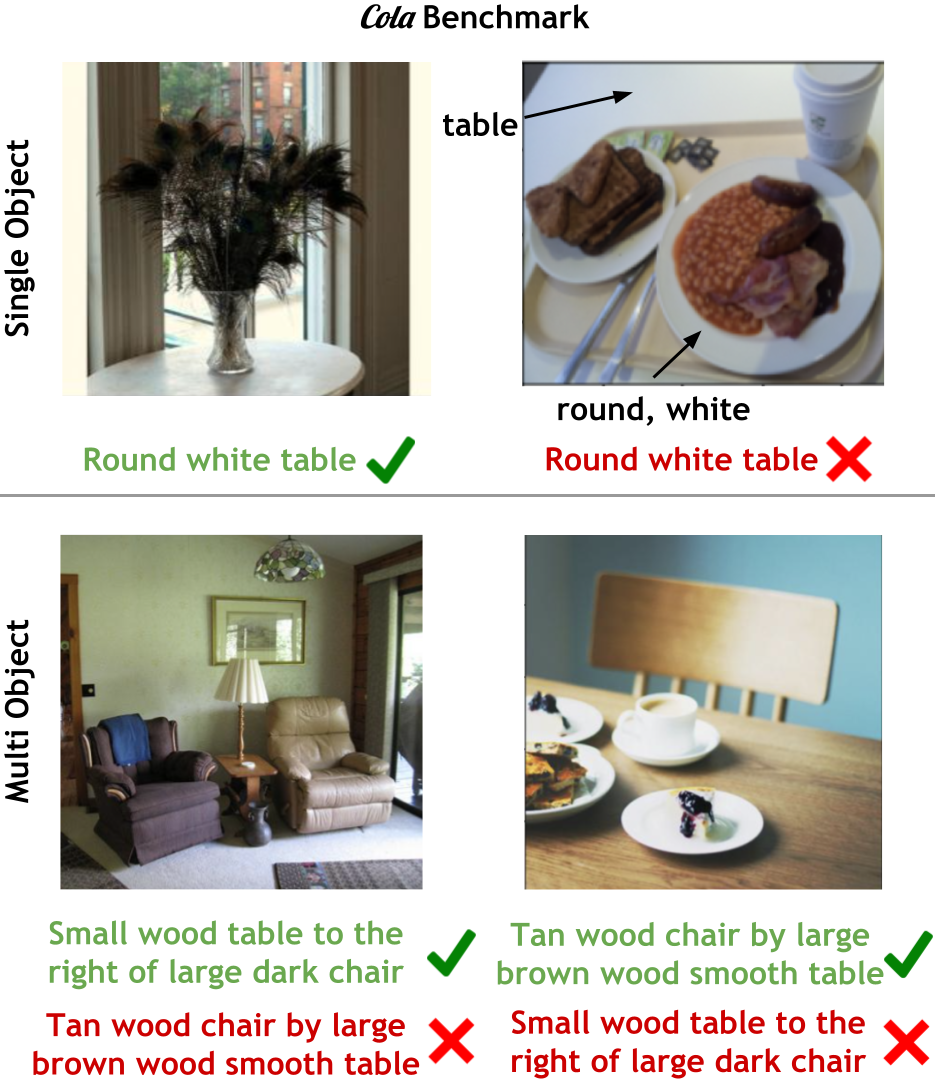
Winoground study compositionality using relationships, but we focus on attribute-object bindings, since finding objects with correct attributes is crucial in many applications. Object-attribute bindings should fundamentally be easier than compositions with relationships; yet, we find that existing models still struggle with this simpler binding.
CREPE evaluates models using image-to-text, whereas we evaluate using text-to-image, where text queries are used to retrieve the correct image from a set of difficult distractor images. Text-to-image retrieval is harder because image encoders are weaker at distinguishing fine-grained differences in images for a given text than text encoders are at distinguishing fine-grained text. Moreover, text-to-image is better aligned with practical applications, such as a user giving text instructions to a machine to find certain objects.
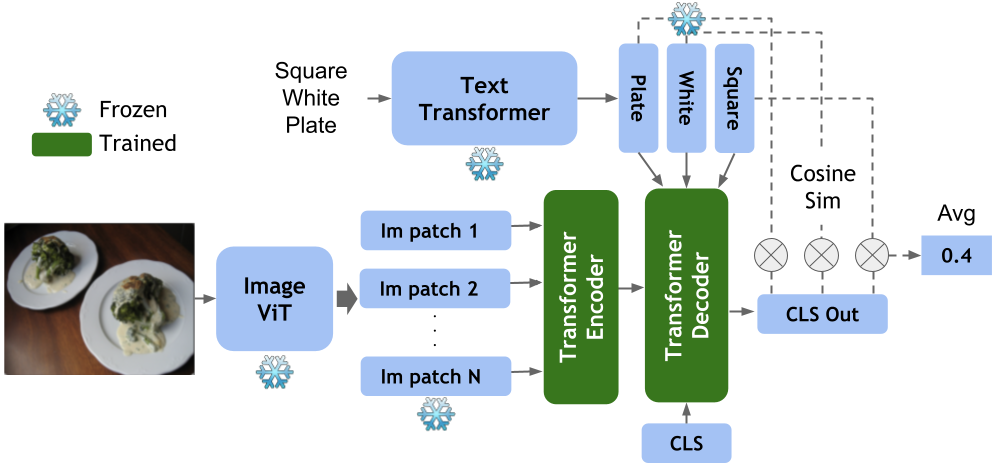
There are probably many more by the time you are reading this. This work adds to the on-going discussion that robust compositionality seems to tbe lacking in many pre-trained large vision-language models. However, we show that they can be easily adapted to exhibit composiotionality if trained with the contrastive data with fine-grained differences.
@misc{ray2023cola,
title={COLA: How to adapt vision-language models to Compose Objects Localized with Attributes?},
author={Arijit Ray and Filip Radenovic and Abhimanyu Dubey and Bryan A. Plummer and Ranjay Krishna and Kate Saenko},
year={2023},
eprint={2305.03689},
archivePrefix={arXiv},
primaryClass={cs.CV}}