Problem Definition
We were given a dataset that consists of JPEG images with objects of three shapes: square cicrle and triange; each shape is filled with its own solid color that is unique for each object in the image. We need to solve the following problems:
- For each shape image, determine its background color and label each and every shape blobs according to their color.
- For each shape blob, implement a border following algorithm to find its outermost contour (i.e. the border pixels).
- For each shape blob, classify its border pixels (in other words, segment its outermost contour) into three types: borders against the background, borders against another shape blob and borders that are a border of the whole image.
- For each shape blob, come up with an algorithm that can recognize its shape type (square, circle, or triangle).
Method and Implementation
Image denoising and labeling. I combined the image denoising with labeling using kmeans clustering algorithm. First, I downsized the original image to find the number of clusters K(downsizing implies loss of some information and reduces variance of the data). I iterated through various values of K and made the decision according to the munimal number of pixels in a cluster (if this number is too small, then K is too large and we probably added a cluster with noise). Then I used kmeans algorithm to cluster the objects according to their colors. Kmeans works reasonably well on this dataset except for two cases: a) if colors of object and/or background are similar and b) if the color of one object is close to the color of the noisy border of another object (see experiments). To solve the latter issue, I used majority vote filter that replaces the color of a pixel if its original color is in the minority within its neighborhood. I also implemented border cleaning algorithm that simply checks if the line of certain color is surrounded by pixels with different colors. The kmeans algorithm followed by majority vote and border cleaning give us both clean version of an image and object labels.
Borderline detection and classification. For borderline detection, I implemented the standard border following algorithm that finds the outermost pixels of the object based on its color. For classification, I compared the border pixels with its N4 neighbors (if at least one neighbor is background then this pixel is border against background).
Shape classification. I used template matching method (cv2.matchShapes) to classify the shapes. It computes the similarity of two images based on their Hu moments. This method works reasonably well but tends to misclassify the significantly overlapping objects.
Experiments
While creating this solution I was wxperimenting with different algorithms and parameters. For example, I tried to use the standard OpenCV data denoising method (cv2.fastNlMeansDenoisingColored), which did not improve the image quality significantly. I also tried to use the bilateral filter for edge-preserving smoothing, but that also did not help to clean the data. I tried different thresholding parameter for minimal cluster size in quantization part and 4% of overall image size proved to be the best choice. I also experimented with the majority vote threshold that determines the minimal number of same color pixels in the neighborhood required to leave the pixel color as it is. I set this parameter to be 25 for a 10x10 window.
For the evaluation I used the confusion matrix and the precision metrics.
Results
Precision = TP/(TP + FP):
- Squares: 0.87
- Circles: 1
- Triangles: 0.79
| - | Square | Circle | Triangle |
|---|---|---|---|
| Square | 246 | 0 | 51 |
| Circle | 31 | 254 | 33 | Triangle | 5 | 0 | 325 |
Results | ||||
| Input | Clean | Classified borders | Classified shapes | |
| Good example 1 |  |
 |
 |
 |
| Good example 2 |  |
 |
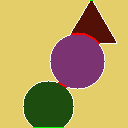 |
 |
| Bad example 1 |  |
 |
 |
 |
| Bad example 2 |  |
 |
 |
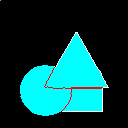 |
Discussion
The described approach can detect and classify simple shapes in noisy images. Since the input images vere heavily distorted by the jpeg compression algorithm, some errors may occur, especially when the boorder around the object has a similar color with another object in the image. Next step in this direction would be to use kmeans for both color and pixel position at the same time. The shape misclassification problem can be solved by using the border curvature and convexity instead of template matching.
Conclusions
The main conclusion of my experiments is that shape matching algorithm does not perform well when the objects overlap. The second main conclusion is to never use a lossy compression when saving images that are meant to be used for computer vision purposes.
Credits and Bibliography
- https://en.wikipedia.org/wiki/Boyer%E2%80%93Moore_majority_vote_algorithm
- https://en.wikipedia.org/wiki/K-means_clustering
- https://en.wikipedia.org/wiki/Quantization_(image_processing)