Problem Definition
In this assignment, we need to implement and analyse neural network on three different datasets, linear dataset, nonlinear dataset, and hand-written digit dataset and observe the influence of learning rate and regularization. The crucial parts of this assignment include: reading and transforming data from datasets to applicable data structure to neural network, implementation of forward and backward propagation algorithm as well as statistics and analysis of performance of neural network.
Method and Implementation
We need to implement a neural network with a hidden layer from source code. We will at first need to use csv file reader to read data from datasets and convert them into numpy array. Then we use computation function in numpy module to implement the computational part in forward and backward propagation algorithm based on mathematical derivation. Finally we compute the confusion matrix to evaluate the performance of neural network using five-fold cross validation.
I use python to implement neural network, and the code consists a class called nn, which contains constuctor to initalize some super parameters of neural network, compute_cost function to compute cost and gradient, activation and de_activation function to compute the output and derivative of an activation function, train function to launch the training process including computing cost and updating weights and a run function to read dataset, start training and evaluating performance using five-fold cross validation. In this assignment, I set up a neural network with one hidden layer with 10 neurons for linear and non linear datasets. For the hand written digit dataset, I built a neural network with a hidden layer with 100 neurons.
Experiments
I conducted four parts of experiments in this assignment. The first part include evaluating performance of neural network on linear and nonlinear datasets using five-fold cross validataion. Confusion matrix and accuracy will be provided.
The second part include evaluating performance of neural network using different learning rate.
The third part is about the effect of different regularization approaches.
The last part is about the performance of the neural network on the hand-written digit dataset. To eliminate randomness during training, I will repeat training for 5 times and sum up the confusion matrix.
For the first part, confusion matrix and accuracy of five-fold cross validation will be provided to evaluate performance of neural network.
For the second part, plot of cost value during the training process will be shown to analyse the influence of learning rate.
For the third part, confusion matrix and accuracy of different regularization parameter will be provided.
For the forth part, confusion matrix and accuracy of test data will be provided.
Results
1) Confusion matrix and accuracy for neural network on linear and non linear datasets.
Confusion Matrix for linear dataset
| 0 | 1 | ||
| 0 | 998 | 1 | |
| 1 | 2 | 999 | |
Confusion Matrix for nonlinear dataset
| 0 | 1 | ||
| 0 | 784 | 13 | |
| 1 | 216 | 987 | |
2) Cost with respect to training epoch on non linear data with different learning rate.
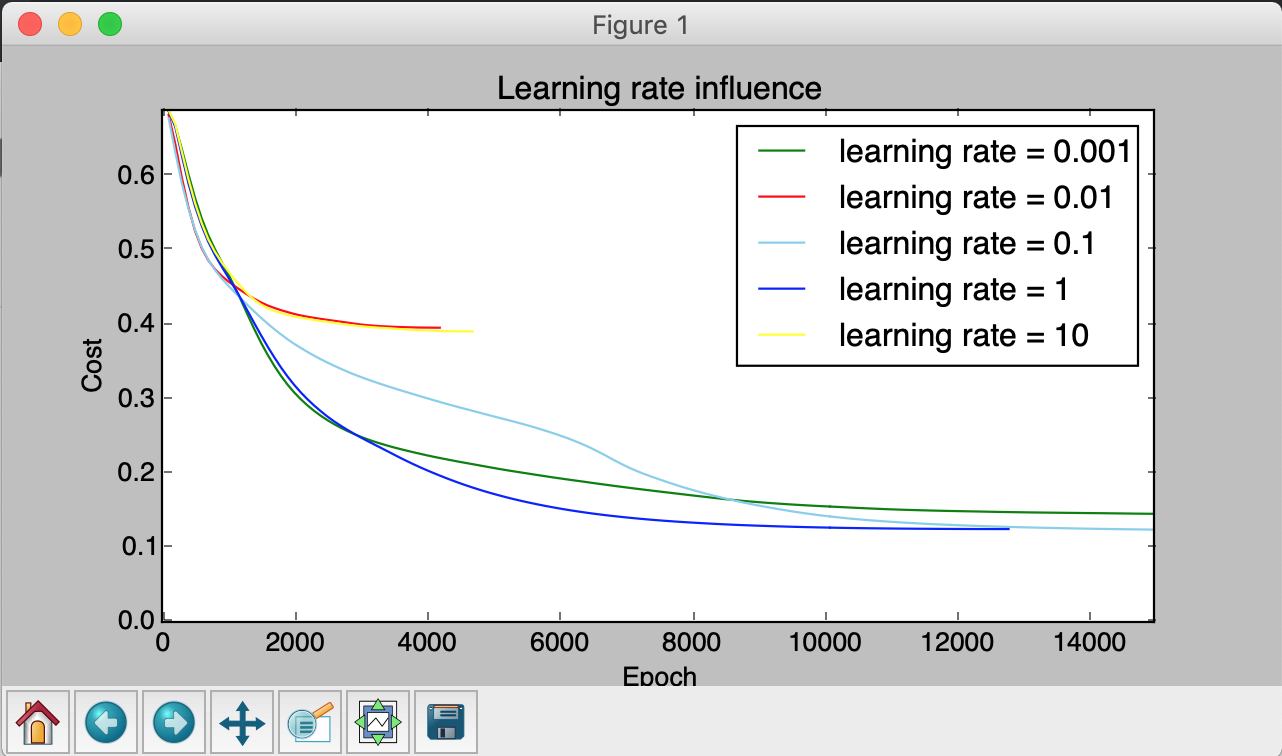
3) Test performance of neural network with different regularization parameter lambda
Confusion Matrix for non linear dataset with lambda = 0
| 0 | 1 | ||
| 0 | 195 | 11 | |
| 1 | 4 | 190 | |
Confusion Matrix for non linear dataset with lambda = 0.01
| 0 | 1 | ||
| 0 | 194 | 10 | |
| 1 | 5 | 191 | |
Confusion Matrix for non linear dataset with lambda = 0.1
| 0 | 1 | ||
| 0 | 195 | 10 | |
| 1 | 4 | 191 | |
Confusion Matrix for non linear dataset with lambda = 1
| 0 | 1 | ||
| 0 | 197 | 3 | |
| 1 | 2 | 198 | |
Confusion Matrix for non linear dataset with lambda = 10
| 0 | 1 | ||
| 0 | 194 | 10 | |
| 1 | 5 | 191 | |
4) Confusion matrix and accuracy for neural network on hand-written digits dataset.
Confusion Matrix for hand-written digits dataset
| label | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 0 | 428 | 0 | 5 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 374 | 0 | 6 | 10 | 0 | 5 | 0 | 15 | 0 | |
| 2 | 0 | 0 | 400 | 5 | 0 | 0 | 0 | 0 | 1 | 0 | |
| 3 | 0 | 5 | 19 | 391 | 0 | 0 | 0 | 0 | 15 | 5 | |
| 4 | 5 | 5 | 0 | 0 | 416 | 0 | 0 | 0 | 6 | 0 | |
| 5 | 7 | 5 | 0 | 15 | 0 | 433 | 0 | 0 | 25 | 19 | |
| 6 | 0 | 5 | 0 | 0 | 22 | 5 | 450 | 0 | 0 | 0 | |
| 7 | 0 | 0 | 0 | 25 | 0 | 0 | 0 | 431 | 5 | 0 | |
| 8 | 0 | 10 | 3 | 13 | 0 | 0 | 0 | 14 | 353 | 0 | |
| 9 | 0 | 51 | 3 | 0 | 10 | 17 | 0 | 0 | 20 | 436 | |
Discussion
- From the first experiment, we can find out that the performance of neural network on linear dataset are very likely to outperform those on non linear dataset. We can actually visualize the non linear dataset then we will find out that the dataset is quiet irregular so that even human cannot make a good classification on it. In addition, the performance of neural network on non linear data is already much better than the performance of logistic regression provided by cousrse website, which proves the advantage in capacity of coping with non linear data of neural network.
- From the second experiment, we can observe that the performance of neural network are compromised when the learning rate is either too small or too large. When learning rate equals to 0.001, it will take more time in training process since it updates its weights in a slower pace. However, when learning rate equals to 10, the performance of neural network is even worse since it was stuck in local minimum so it was terminated eariler with high cost value. We shall notice that the performance are sometimes no the regular when learning rate are between 0.001 and 10. However, since training process are highly randomized, it is reasonable that sometimes moderate learning rate cause worse performance or extreme learning rate cause better performance.
- From the third experiment, we may find that the performance of neural network on non linear increase when lambda increase from 0 to 1 and decrease when it increase from 1 to 10, which indicates that a moderate lambda is helpful in preventing over fitting but backfires when it becomes too large since it will limit the learning capacity of neural network.
- In the forth experiment, we implemented a neural network on a real-world dataset, and the result turns out to be inspiring since it reached accuracy of 91% using just a neural network with one hidden layer. However, the model is probably still not deep and large enough to have the capacity to fully learn to shape of digits. From the confusion matrix we may notice that "1" is very likely to be recognized as "9" because of the similarity of shape of them. I am optimistic about the improvement of the performance if more training data, a deeper model and better training strategy are applied.
Conclusions
In this assignment, I implemented two neural networks from source code with reasonable size with respect to the input and output size of the model so that they will less likely to suffer from under fitting or over fitting.
We also can conclude that it is of importance to choose reasonable super parameters such as learning rate, regularization parameter, number of neuron in hidden layer in neural network. Other advanced approaches to train a neural network such as using ReLu activation function, dropout, etc. are also recommended.
Credits and Bibliography
Datsets used in this assignment are downloaded from course website of CS640.