|
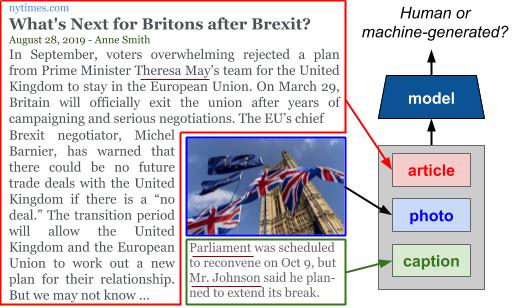 Large-scale dissemination of disinformation online intended to mislead or deceive the general population is a major societal problem. Rapid progression in image, video, and natural language generative models has only exacerbated this situation and intensified our need for an effective defense mechanism. While existing approaches have been proposed to defend against neural fake news, they are generally constrained to the very limited setting where articles only have text and metadata such as the title and authors. In this paper, we introduce the more realistic and challenging task of defending against machine-generated news that also includes images and captions. To identify the possible weaknesses that adversaries can exploit, we create a NeuralNews dataset composed of 4 different types of generated articles as well as conduct a series of human user study experiments based on this dataset. In addition to the valuable insights gleaned from our user study experiments, we provide a relatively effective approach based on detecting visual-semantic inconsistencies, which will serve as an effective first line of defense and a useful reference for future work in defending against machine-generated disinformation.. NeuralNews DatasetThe NeuralNews dataset consists of human-generated and machine-generated articles. To obtain the human-generated articles, we build NeuralNews on top of the GoodNews dataset, which is extracted from the New York Times. The Grover model is used to generate articles using the human-generated titles and articles as context. To download the articles used in our experiments, you can do so using this link. To download the images, captions and metadata, please go to this link and follow the instructions to download the images and captions. DIDAN Model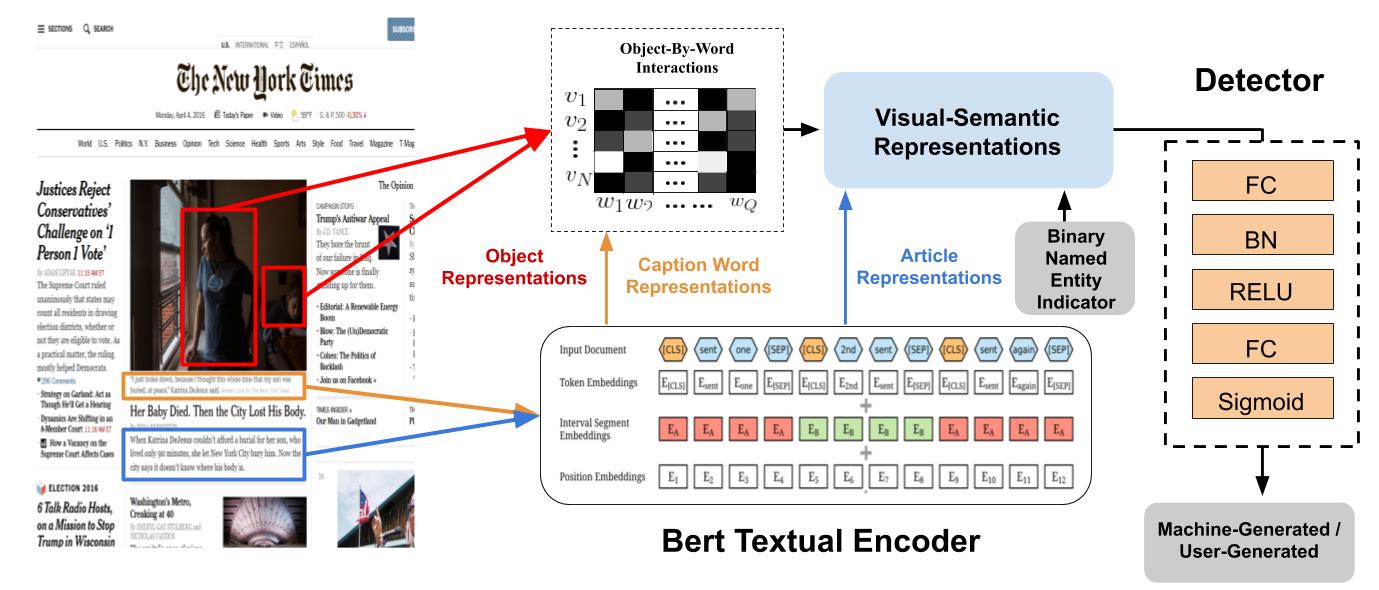 DIDAN is a multimodal model that accepts an article as well as its images and captions as inputs and predicts if it is human-generated or machine-generated. To determine the origin of an article, DIDAN seeks to detect visual-semantic inconsistency between the article and the image and caption. By incorporating article context into a visual-semantic representation computed from an image and a caption, it reasons about relationships between named entities present in the article and the image or caption. You can find the code here.
|
Reference
If you find this useful in your work please consider citing:
@InProceedings{tanDIDAN2020,
author={Reuben Tan and Bryan A. Plummer and Kate Saenko},
title={Detecting Cross-Modal Inconsistency to Defend Against Neural Fake News},
booktitle={Empirical Methods in Natural Language Processing (EMNLP)},
year={2020} }