|
 We introduce the task of spatially localizing narrated interactions in videos. Key to our approach is the ability to learn to spatially localize interactions with self-supervision on a large corpus of videos with accompanying transcribed narrations. To achieve this goal, we propose a multilayer cross-modal attention network that enables effective optimization of a contrastive loss during training. We introduce adivided strategy that alternates between computing inter- and intra-modal attention across the visual and natural language modalities, which allows effective trainingvia directly contrasting the two modalities' representations. We demonstrate theeffectiveness of our approach by self-training on the HowTo100M instructional video dataset and evaluating on a newly collected dataset of localized described interactions in the YouCook2 dataset. We show that our approach outperforms alternative baselines, including shallow co-attention and full cross-modal attention. We also apply our approach to grounding phrases in images with weak supervision on Flickr30K and show that stacking multiple attention layers is effective and, when combined with a word-to-region loss, achieves state of the art on recall-at-one and pointing hand accuracies.. YouCook2-Interactions DatasetThe YouCook2-Interactions evaluation dataset contains frame-level bounding box annotations for described interactions in instructional cooking videos. It is built on top of the original YouCook2 dataset, which contains temporal segment annotations. To download the YouCook2-Interactions dataset, you can do so using this link. We note that the videos in our dataset are sourced from the validation split of the YouCook2 dataset. Contrastive Multilayer Multimodal Attention Model (CoMMA)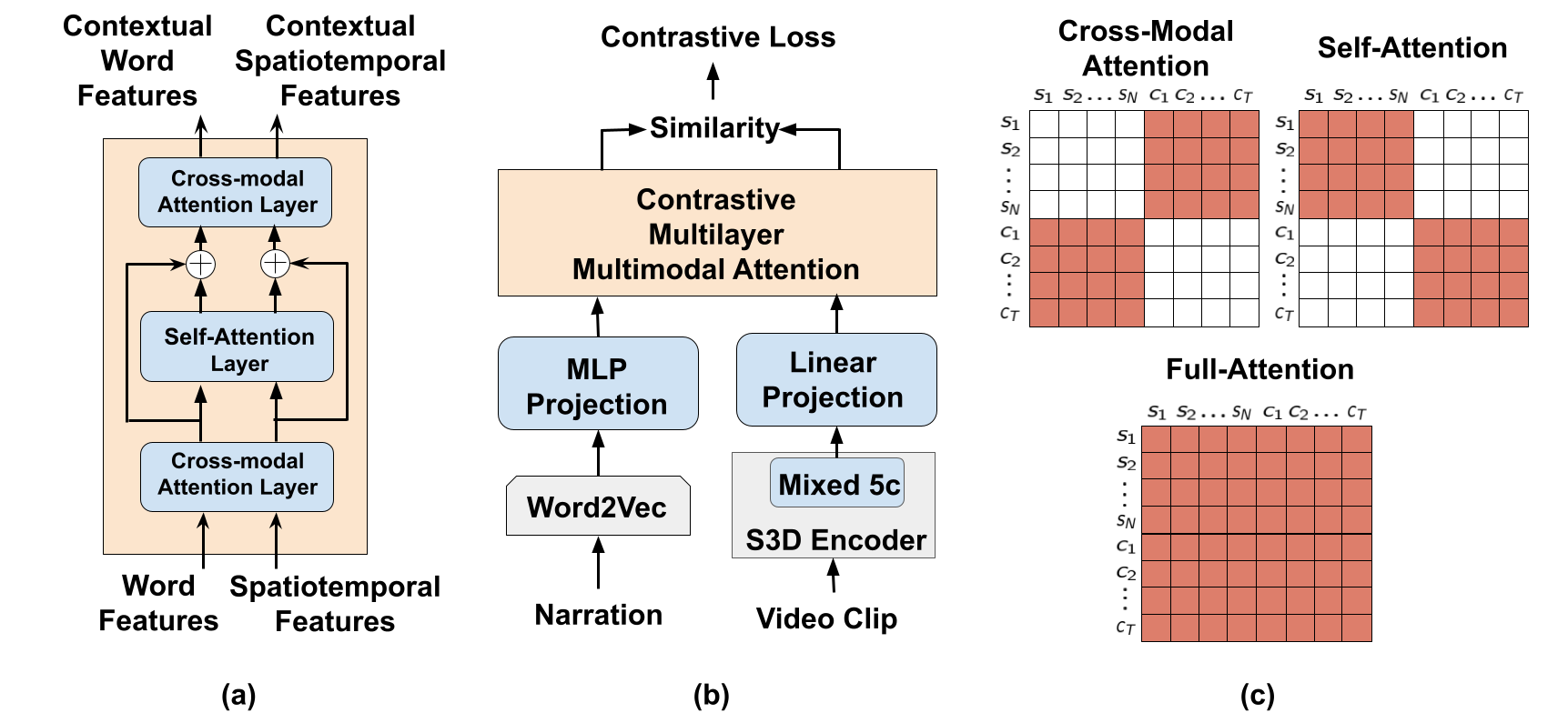 To address the task of self-supervised spatial grounding of narrations in videos, we propose the Contrastive Multilayer Multimodal Attention (CoMMA) module. It comprises alternating bidirectional cross-modal and self-attention layers to encourage a fine-grained alignment between spatiotemporal and word features. Additionally, it is also model-agnostic and can be applied on top on any base visual and lanaguage encoders. You can find the code here.
|
Reference
If you find this useful in your work please consider citing:
@inproceedings{tanCOMMA2021,
author = {Reuben Tan and Bryan A. Plummer and Kate Saenko and Hailin Jin and Bryan Russell},
title = {Look at What Im Doing: Self-Supervised Spatial Grounding of Narrations in Instructional Videos},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021} }