DualCoOp: Fast Adaptation to Multi-Label Recognition with Limited Annotations
Abstract
Solving multi-label recognition (MLR) for images in the low-label regime is a challenging task with many real-world applications. Recent work learns an alignment between textual and visual spaces to compensate for insufficient image labels, but loses accuracy because of the limited amount of available MLR annotations. In this work, we utilize the strong alignment of textual and visual features pretrained with millions of auxiliary image-text pairs and propose Dual Context Optimization (DualCoOp) as a unified framework for partial-label MLR and zero-shot MLR. DualCoOp encodes positive and negative contexts with class names as part of the linguistic input (i.e. prompts). Since DualCoOp only introduces a very light learnable overhead upon the pretrained vision-language framework, it can quickly adapt to multi-label recognition tasks that have limited annotations and even unseen classes. Experiments on standard multi-label recognition benchmarks across two challenging low-label settings demonstrate the advantages of our approach over state-of-the-art methods.
Overview
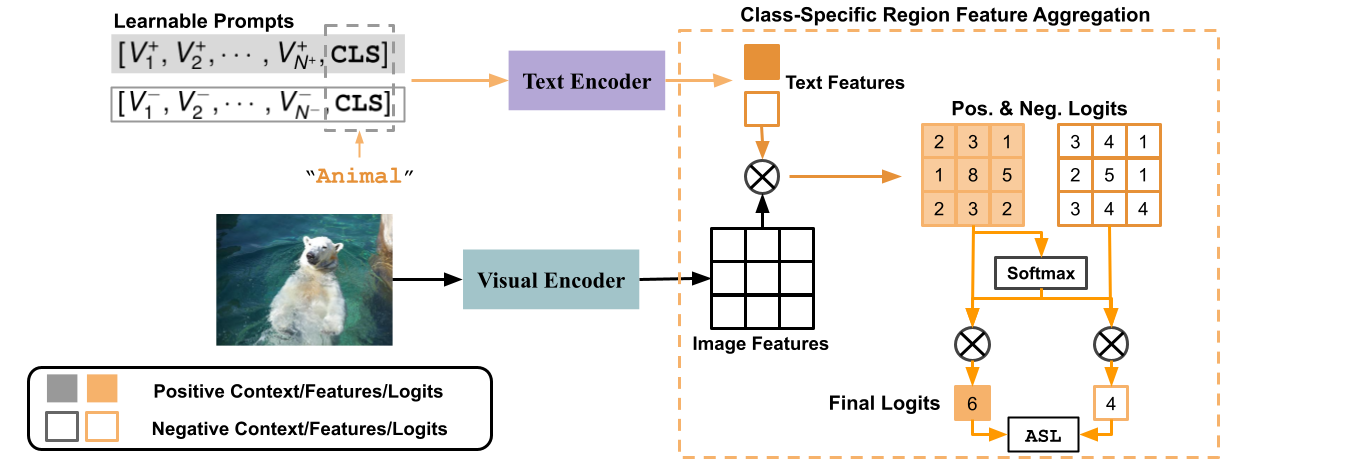
To compensate for insufficient or missing image labels, it is important to learn how the meanings of category names are related to each other, so we can transfer knowledge between related categories. This is usually done by learning an alignment between the visual and textual spaces. However, our dataset is too limited to learn a broad and generalizable mapping. We propose DualCoOp to instead leverage the strong alignment of visual and textual feature spaces learned by large-scale vision-language pretraining (CLIP) with a light-weight learnable overhead which quickly adapts to the MLR task with limited semantic annotations. Figure~\ref{fig:model_overview} provides an overview of our proposed approach. DualCoOp learns a pair of ``prompt'' contexts in the form of two learnable sequences of word vectors, to provide positive and negative contextual surroundings of a given category name $m$. This generates positive and negative textual features that are fed into the pretrained text encoder. Furthermore, to better recognize multiple objects, which can be located at different locations in the image, the spatial aggregation step is modified. We first compute the similarity score of each projected visual feature at location to obtain prediction logits over regions. For each class, we perform aggregation of all spatial logits, in which the weight for each logit is determined by its relative magnitude. We call this Class-Specific Region Feature Aggregation. During training, we optimize the learnable prompts via the ASL loss while keeping all other network components frozen. During inference, we directly compare the final positive and negative logits to make a prediction for each label
Code
The code to prepare data and train the model can be found in: https://github.com/sunxm2357/DualCoOp