Dynamic Network Quantization for Efficient Video Inference
Abstract
Deep convolutional networks have recently achieved great success in video recognition, yet their practical realization remains a challenge due to the large amount of computational resources required to achieve robust recognition. Motivated by the effectiveness of quantization for boosting efficiency, in this paper, we propose a dynamic network quantization framework, that selects optimal precision for each frame conditioned on the input for efficient video recognition. Specifically, given a video clip, we train a very lightweight network in parallel with the recognition network, to produce a dynamic policy indicating which numerical precision to be used per frame in recognizing videos. We train both networks effectively using standard backpropagation with a loss to achieve both competitive performance and resource efficiency required for video recognition. Extensive experiments on four challenging diverse benchmark datasets demonstrate that our proposed approach provides significant savings in computation and memory usage while outperforming the existing state-of-the-art methods.
Overview
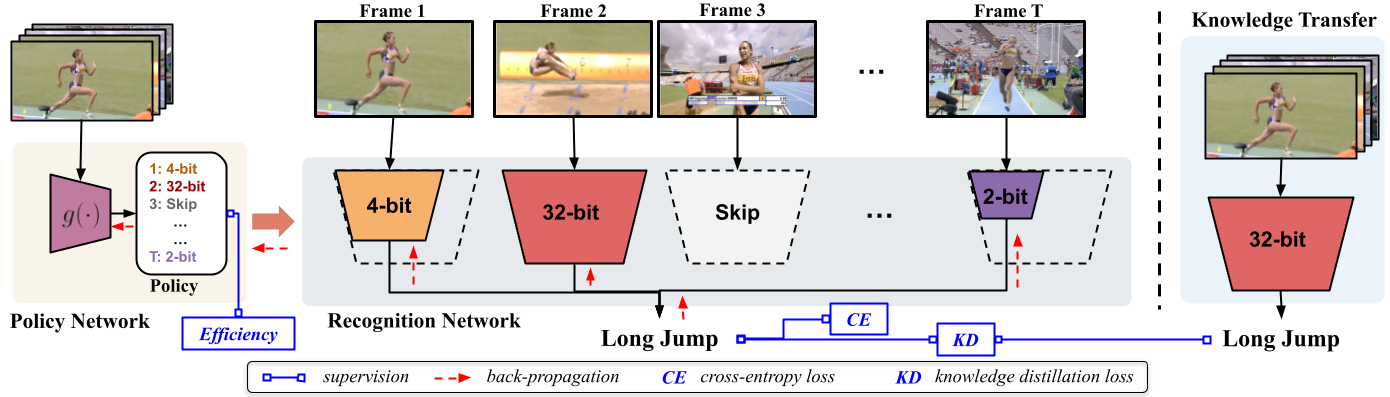
VideoIQ consists of a very lightweight policy network and a single backbone network for recognition which can be simply quantized to lower precisions by truncating the least significant bits. The policy network decides what quantization precision to use on a per frame basis, in pursuit of a reduced overall computational cost without sacrificing recognition accuracy. We train both networks using back-propagation with a combined loss of standard cross-entropy and efficiency for video recognition. We additionally distill knowledge from a pre-trained full-precision model to guide the training of lower precisions. During inference, each frame is sequentially fed into the policy network to select optimal precision for processing the current frame through the recognition network and then the network averages all the frame-level predictions to obtain the video-level prediction.
Code
The code to prepare data and train the model can be found in: https://github.com/sunxm2357/VideoIQ
Reference
If you find this useful in your work please consider citing:
@InProceedings{Sun_2021_ICCV,
author = {Sun, Ximeng and Panda, Rameswar and Chen, Chun-Fu (Richard) and Oliva, Aude and Feris, Rogerio and Saenko, Kate},
title = {Dynamic Network Quantization for Efficient Video Inference},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {7375-7385}
}