Research activities
Distributed, private algorithms
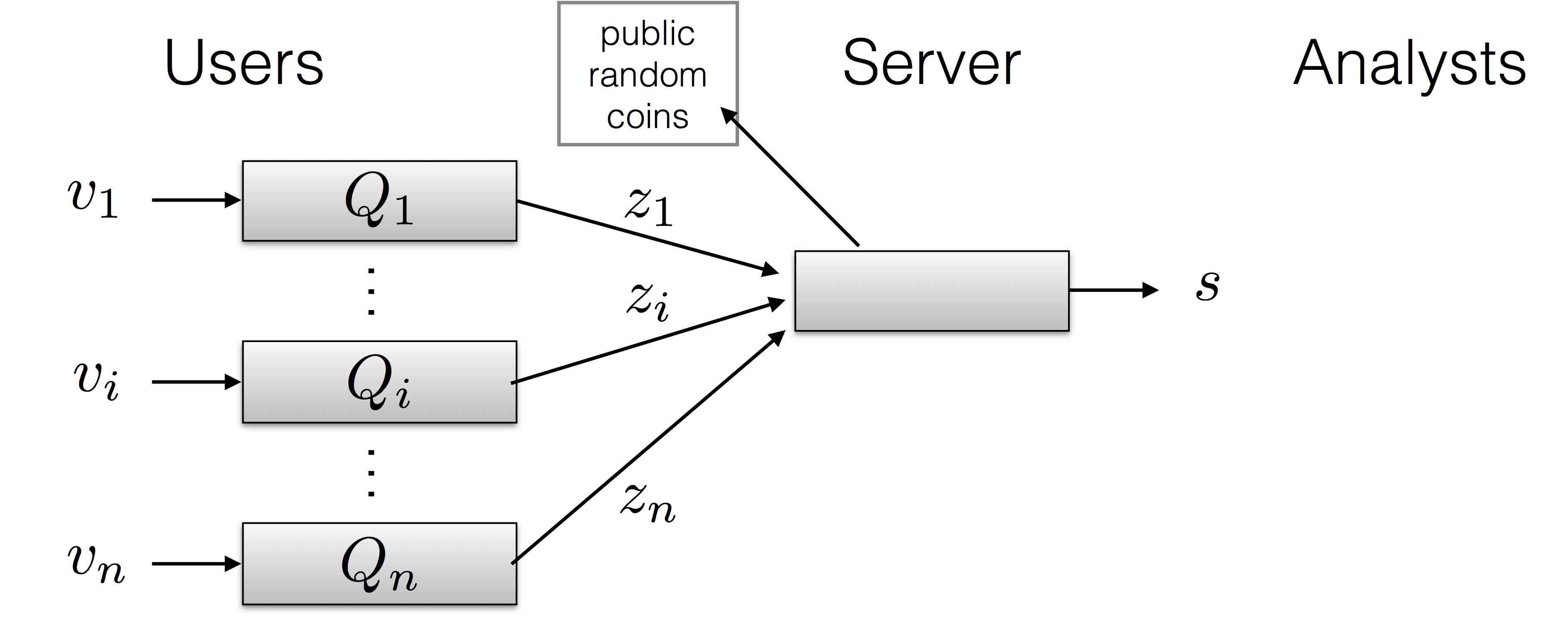
The local, or randomized response model of privacy is one in which each individual retains their raw data, and sends only a randomized version of their data (a "report") to some central aggregator who computes a global summary based on those reports. In this part of the project, we are developing and evaluating new algorithms for constructing approximate histograms of discrete data. We show that our algorithms have asymptotically optimal accuracy among all local differentially private algorithms.
Publications: [BS15]
Streaming algorithms for private data analysis
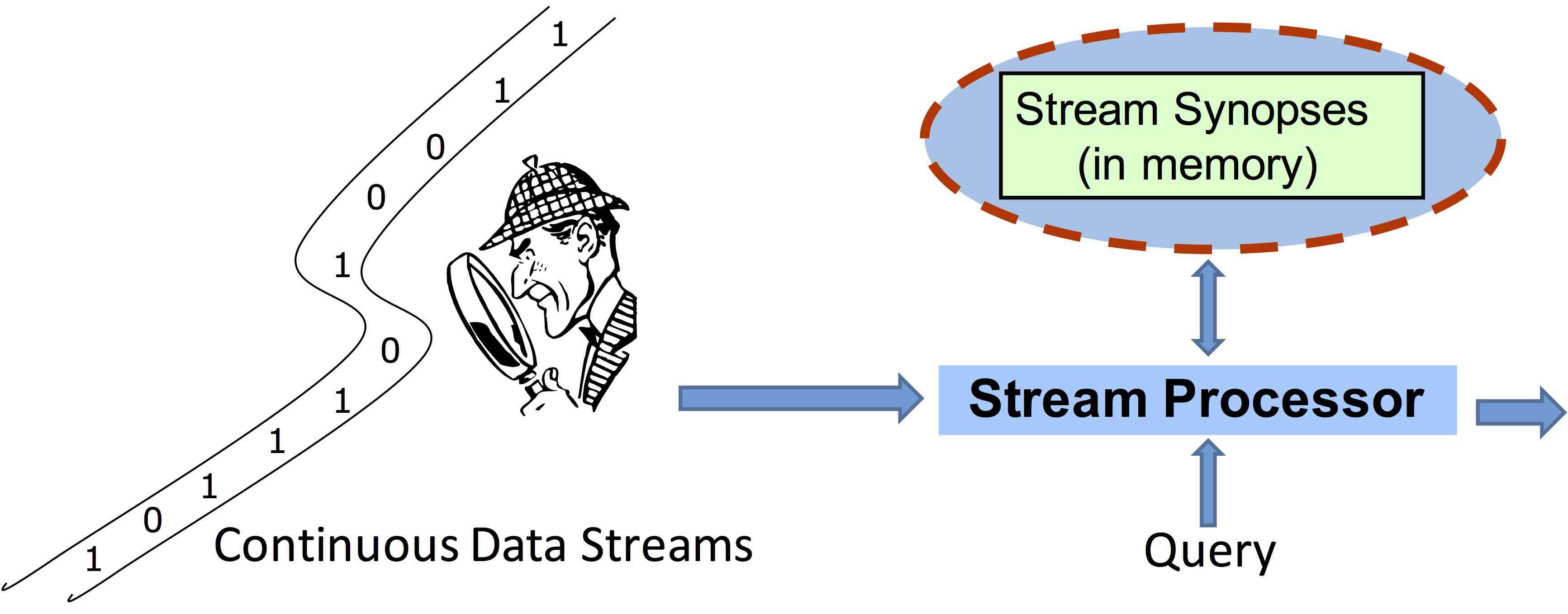
Algorithms must often process data sets that are far larger than what can feasibly fit in the memory of a single machine. Streaming algorithms make a single pass over a large data set with a relatively small amount of memory. We are developing efficient and scalable differentially private algorithms for linear algebraic problems such as low-rank approximation and principal component analysis.
Publications: [U16]
Tracing attacks on perturbed statistics
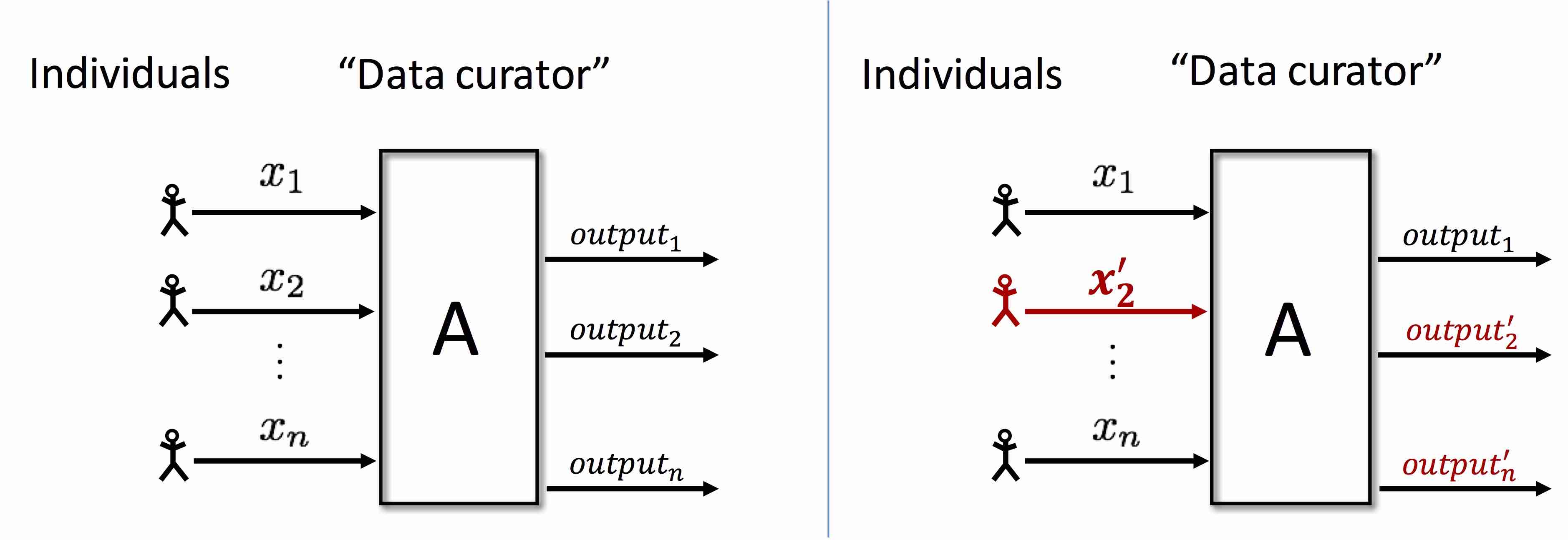
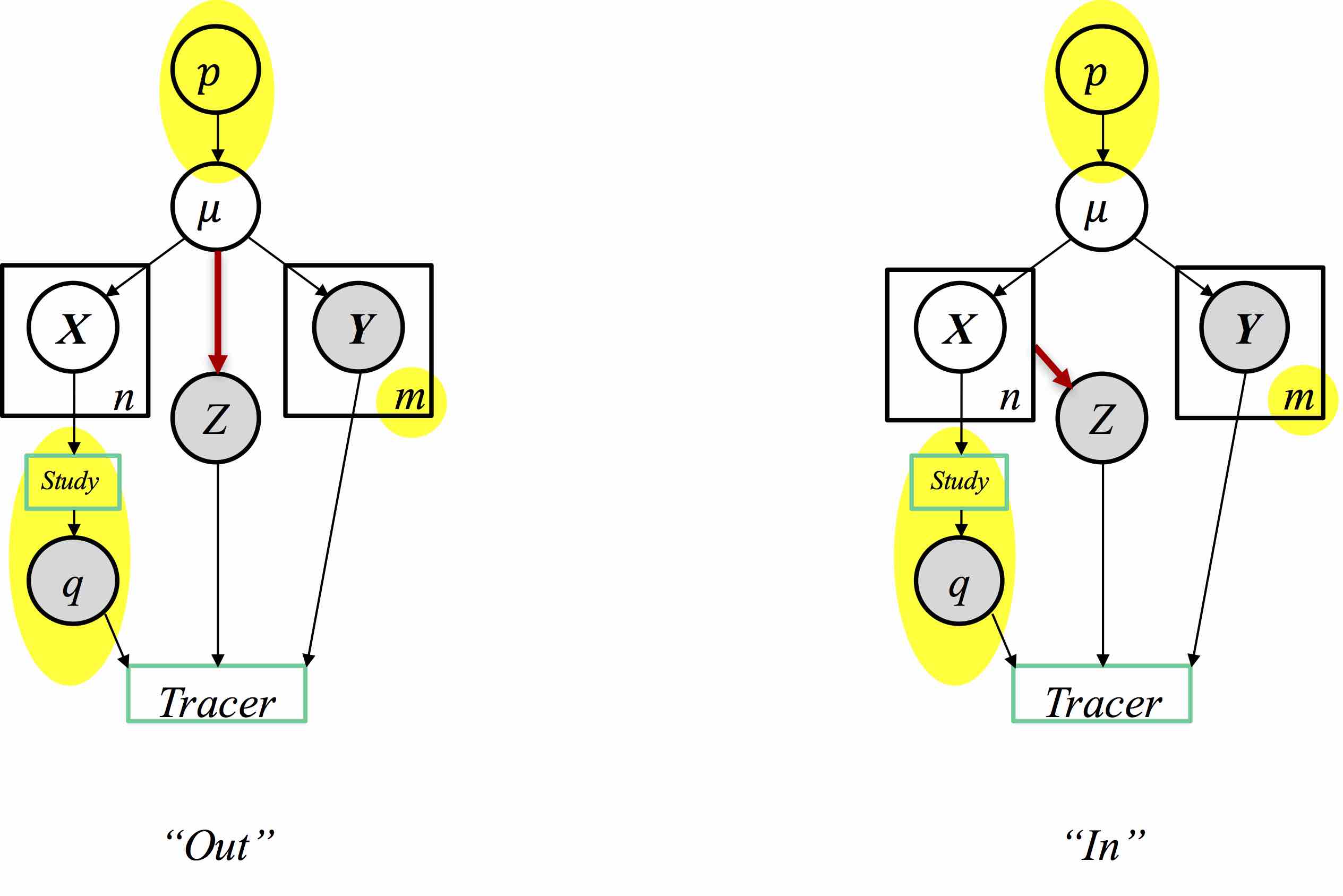
The privacy risks inherent in the release of a large number of summary statistics were illustrated by Homer et al. (PLoS Genetics, 2008), who considered the case of SNP allele frequencies obtained in a genome-wide association study: Given a large number of minor allele frequencies from a case group of individuals diagnosed with a particular disease, together with the genomic data of a single target individual and statistics from a sizable reference dataset independently drawn from the same population, an attacker can determine with high confidence whether or not the target is in the case group.
As part of this project, we consider attacks that succeeds even if the summary statistics are significantly distorted, whether due to measurement error or noise intentionally introduced to protect privacy. Our new attacks are not specific to genomics and handle Gaussian as well as Bernouilli data. The attacks work essentially whenever the released statistics come with less distortion than the amount of noise added by a known differentially private algorithm based on additive noise. Technically, the attacks vastly generalize existing lower bounds on differential privacy, based on fingerprinting codes.
Publications: [DSSUV15]