
Showan Asyabi
Data and Computer systems researcher and CS Ph.D. candidate at Boston university
Boston, MA
easyabi@bu.edu
When I am not doing research, I travel with friends, explore Boston restaurants, or play different types of sports. I also spend time developing my own stream processor engine!
Find me on social media:
News
March 2023
Thrilled to join Oracle's Exascale team! Eager to contribute to Oracle's cutting-edge data systems!
February 2023
I successfully defended my Ph.D. thesis, titled "Resource-efficient, performant in-memory KV stores for at-scale data centers."
January 2022
I am very glad to share that our paper (Gadget) was accepted at EuroSys 22
January 2022
I am very glad to share that our paper (Gadget) was accepted at EuroSys 22
November 2021
I am so excited to present Gadget at Google. Gadget is a system we built to evaluate persistent KV stores for stream processing systems.
March 2021
My work on stream processing systems was accepted for presentation at the EuroSys Doctoral Workshop (EuroDW 2021)
March 2021
I am very excited to share that I will join the Infrastructure Optimization and Performance team at Twitter as a research intern this summer!
August 2020
Our paper (Peafowl) got accepted in ACM Symposium on Cloud Computing 2020 (SoCC '2020)
May 2020
I am so excited to announce that I will be joining MIT's Tim Kraska at einblick.ai for a summer internship on database systems.
Febraury 2019
Our paper (Yawn) got accepted in ACM Asia Pacific Workshop on Systems (APSYS 19)
About Me
I'm a CS Ph.D. candidate and computer and data systems researcher.
Research Intersts:
- Stream Processing Systems
- Large Scale Key-Value Stores and Caching Systems
- Operating Systems and Cloud Computing
My research mainly focuses on designing and building data systems.
I have designed and built practical and scalable systems that improve big data systems and data centers' throughput, latency performance,
resource usage efficiency, and energy efficiency.
I am fortunate to be advised by Professor Azer Bestavros. I was also lucky to work with Professors Timothy Zhu and Dr. Emanuel Zgraggen .
I am open to collaborations, so if you have a cool idea and want to discuss it, feel free to email me!
Publications
Gadget: A New Benchmark Harness for Systematic and robust Evaluation of Streaming State Stores
E Asyabi, Y Wang, J Liagouris, V Kalavri, and A Bestavros. EuroSys '22: Proceedings of the Seventeenth European Conference on Computer Systems
Peafowl: In-application CPU Scheduling to Reduce Power Consumption of In-memory Key-Value Stores
E Asyabi , A Bestavros, E Sharafzadeh,T Zhu-
ACM Symposium on Cloud Computing 2020 (SoCC '20)
CTS: An operating system cpu scheduler to mitigate tail latency for latency-sensitive multi-threaded applications
E Asyabi, E Sharafzadeh, SA SanaeeKohroudi, M Sharifi-
Journal of Parallel and Distributed Computing (2019)
Yawn: A CPU Idle-state Governor for Datacenter Applications
E Sharafzadeh, SAS Kohroudi, E Asyabi , M Sharifi
Proceedings of the 10th ACM SIGOPS Asia-Pacific Workshop on Systems (2019)
TerrierTail: mitigating tail latency of cloud virtual machines
E Asyabi , SA SanaeeKohroudi, M Sharifi, A Bestavros -
IEEE Transactions on Parallel and Distributed Systems (2018)
ppXen: A hypervisor CPU scheduler for mitigating performance variability in virtualized clouds
E Asyabi, M Sharifi, A Bestavros-
Future Generation Computer Systems (2018)
Kani : a QoS-aware hypervisor-level scheduler for cloud computing environments
E Asyabi , A Azhdari, M Dehsangi, MG Khan, M Sharifi, SV Azhari -
Cluster Computing (2016)
cCluster: a core clustering mechanism for workload-aware virtual machine scheduling
M Dehsangi, E Asyabi , M Sharifi, SV Azhari -
2015 3rd International Conference on Future Internet of Things and Cloud (2015)
Internships
Twitter - Summer 2021
I am designing and developing a KV store for timeline caching. The project goal is to increase memory efficiency and scalability while offering high read and write throughput. In addition, I am researching the use of persistent memory for timeline caching.
Einblick- Summer 2020
Einblick is an MIT-based startup founded by Tim Kraska . Einblick allows data scientists to build accurate, high-performance models more quickly and make them available to decision-makers. In Einblick, I researched an OLAP architecture that tries to process data mainly in the cache (i.e., in-cache execution). Over my time in Einblick, I designed a new architecture based on the Arrow framework for in-cache execution of queries like hash aggregation and built it over the summer. Our experiments showed the new architecture was up to four times faster.
TALKS
Persistent KV stores tailored for stream processing systems
Singularity-Data - March 2022 link - Slides
Fast, easy, and correct evaluation of state stores for
stream processing systems
Google - November 2021 - Slides
Toward workload-aware state management in stream processing systems
The EuroSys Doctoral Workshop (EuroDW 2022) - April 2021 - PDF -Video - Slides
A Survey on in-memory key-value store designs for today’s data centers
Boston University - December 2021 -PDF - Slides
Peafowl: in-application CPU scheduling to reduce power consumption of in-memory key-value stores
Virtual ACM Symposium on Cloud Computing 2020 (SoCC '20) - October 2020 - PDF - Slides - Video - Poster
RESEARCH PROJECTS
Stream Processing Systems
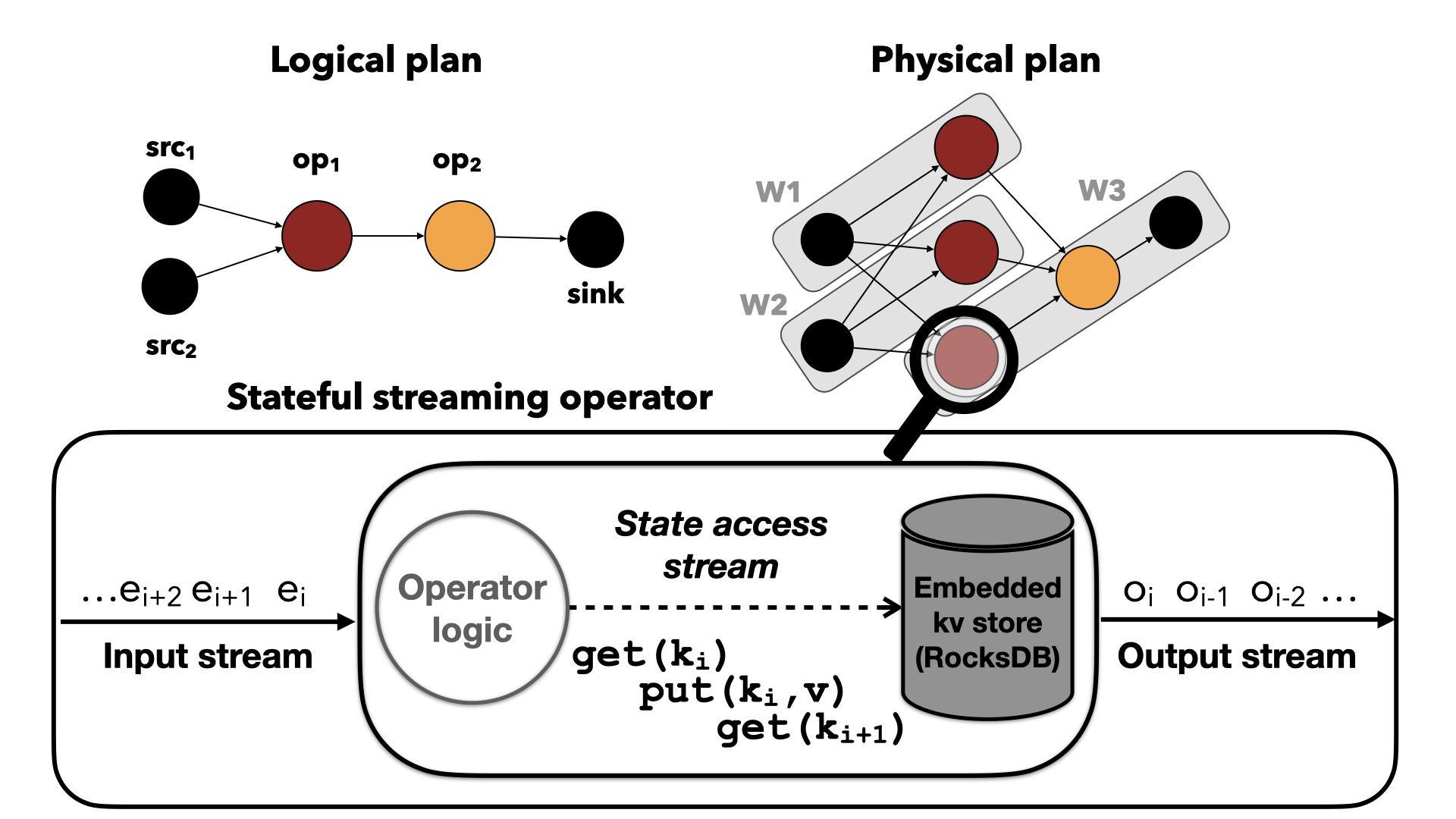 In this project, I aim to enhance Stream Processing Systems (SPSs)
throughput by understanding SPS's state workloads and then designing
KV stores tailored for SPSs. I have performed a thorough empirical
characterization study on state workloads I gathered from instrumenting
Flink and RocksDB. Our analysis highlights the main characteristics of
state store workloads in SPSs. We then designed a benchmarking system
that enables easy and systematic evaluation of streaming state stores.
We presented the results of our research at Eurosys 2022 conference.
This research paper first highlights the overlooked characteristics of
state workloads in stream processing systems. It then presents Gadget,
a benchmarking system we built for robust and systematic evaluation of
state stores used for stream processing systems. Please see the Gadget paper for more details.
My research now focuses on designing a persistent KV store for stream processing systems.
In this project, I aim to enhance Stream Processing Systems (SPSs)
throughput by understanding SPS's state workloads and then designing
KV stores tailored for SPSs. I have performed a thorough empirical
characterization study on state workloads I gathered from instrumenting
Flink and RocksDB. Our analysis highlights the main characteristics of
state store workloads in SPSs. We then designed a benchmarking system
that enables easy and systematic evaluation of streaming state stores.
We presented the results of our research at Eurosys 2022 conference.
This research paper first highlights the overlooked characteristics of
state workloads in stream processing systems. It then presents Gadget,
a benchmarking system we built for robust and systematic evaluation of
state stores used for stream processing systems. Please see the Gadget paper for more details.
My research now focuses on designing a persistent KV store for stream processing systems.
in-Memory Key-Value Store and Caching Systems
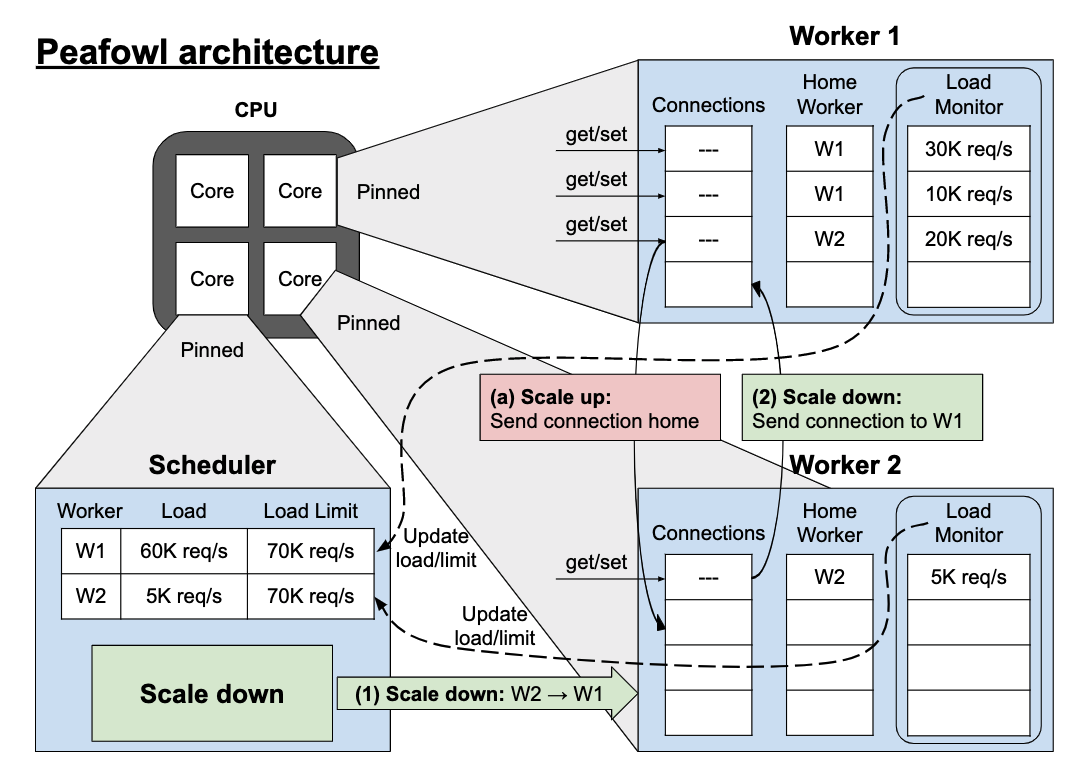 In these projects,
I am researching the throughput, scalability, and resource efficiency of in-memory KV stores
(please see my short survey on in-memory KV stores presented at Boston University).
I am now researching an in-memory KV store for timeline\timeseries caching to increase memory
efficiency while offering high throughput. Before this project, I redesigned the Memcached KV store to mitigate its power consumption.
My studies demonstrate that existing power-saving approaches are ineffective when it comes to short service time and the high arrival rate of in-memory KV stores.
In this project, I have transferred the scheduler from the operating system to Memcached, where there is more domain-specific knowledge.
Our evaluations show that our KV store (Peafowl) reduces power consumption while offering microsecond-level tail latency.
We have presented this research at ACM Symposium on Cloud Computing 2021 (SOCC 21). Please see the Peafowl paper for more detail.
In these projects,
I am researching the throughput, scalability, and resource efficiency of in-memory KV stores
(please see my short survey on in-memory KV stores presented at Boston University).
I am now researching an in-memory KV store for timeline\timeseries caching to increase memory
efficiency while offering high throughput. Before this project, I redesigned the Memcached KV store to mitigate its power consumption.
My studies demonstrate that existing power-saving approaches are ineffective when it comes to short service time and the high arrival rate of in-memory KV stores.
In this project, I have transferred the scheduler from the operating system to Memcached, where there is more domain-specific knowledge.
Our evaluations show that our KV store (Peafowl) reduces power consumption while offering microsecond-level tail latency.
We have presented this research at ACM Symposium on Cloud Computing 2021 (SOCC 21). Please see the Peafowl paper for more detail.
Clouds and Operating Systems
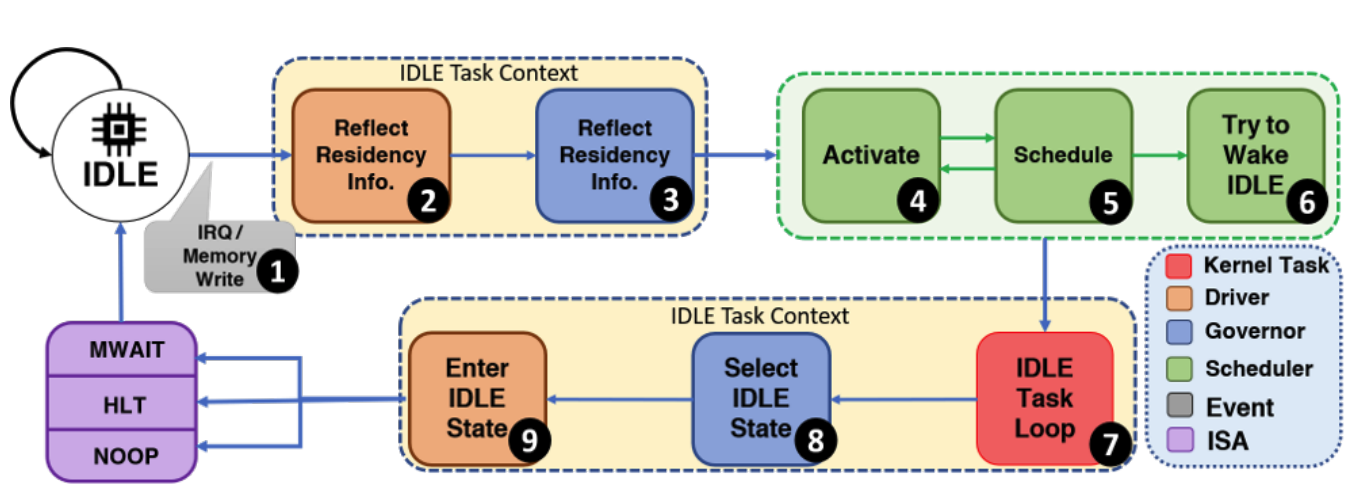 I have designed and built multiple hypervisor schedulers based on Xen to improve virtualized clouds'
latency performance (TerrierTail), predictability (ppXen), utilization (Akita), and QoS (Kani).
I have also redesigned the Linux CFS scheduler and its menu governor to improve the latency (CTS) and power consumption (Yawn) of data centers running on Linux.
Please see Terretail, ppXen, Akita, CTS, Yawn, and Kani papers for more details.
I have designed and built multiple hypervisor schedulers based on Xen to improve virtualized clouds'
latency performance (TerrierTail), predictability (ppXen), utilization (Akita), and QoS (Kani).
I have also redesigned the Linux CFS scheduler and its menu governor to improve the latency (CTS) and power consumption (Yawn) of data centers running on Linux.
Please see Terretail, ppXen, Akita, CTS, Yawn, and Kani papers for more details.
TEACHING
Teaching Fellow for Fundamentals of Computing Systems (CS350)
Boston University: Spring 2019, Fall 2019, Spring 2020, and Fall 2020
Teaching Fellow for Advanced Software Systems (CS410)
Boston University: Fall 2017
MENTORING
Erfan Sharafzadeh , Master student
Erfan is now a CS PhD student at Johns Hopkins University
Alireza Sanaee , Master student
Alireza is now a CS PhD student at Queen Mary University
Amin Fallahi , Undergraduate student
Amin is now a CS PhD studnet at Syracuse University
SKILLS
Pogramming Langauges:
C, C++, Python, Rust, Java, C#
Data processing systems:
Apache Flink, Apache Arrow, Apache Kafka
Machine learning tools:
Scikit Learn, PyTorch