|
Andrea's graduate coursework includes:
Andrea intends to defend by the end of 2023. She is open to postdoctoral positions and full-time industry roles. Her research focus includes representation learning with structured multimodal data and understanding actions in visual environments in tasks such as vision-language navigation. aburns4 [at] bu.edu | CV | LinkedIn | Google Scholar |

|
|
|
I have explored several topics in computer vision and natural language processing including visually enhanced word embeddings, multilingual language representations, image captioning, visual speech recognition, sentiment analysis, and more. Below I include works published in conferences and workshops; other research projects can be found in the project section below. |
 |
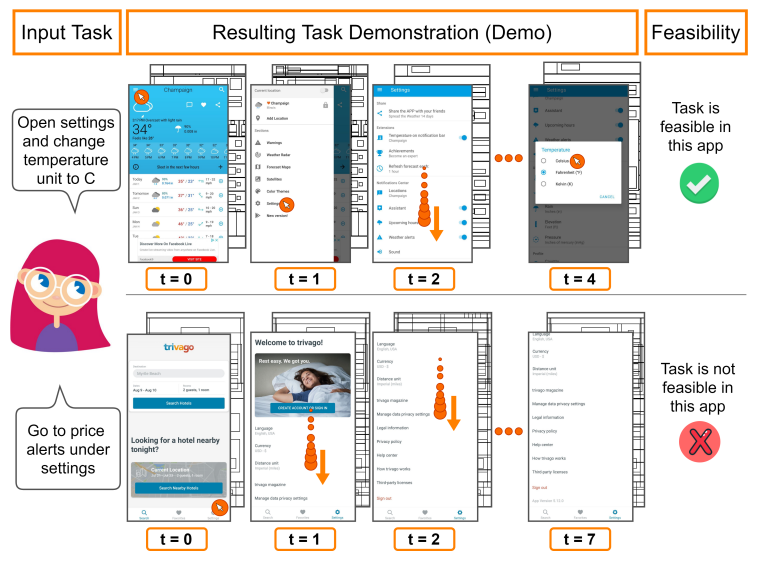
Vision-language navigation (VLN), in which an agent follows language instruction in a visual environment, has been studied under the premise that the input command is fully feasible in the environment. Yet in practice, a request may not be possible due to language ambiguity or environment changes. To study VLN with unknown command feasibility, we introduce a new dataset Mobile app Tasks with Iterative Feedback (MoTIF), where the goal is to complete a natural language command in a mobile app. Mobile apps provide a scalable domain to study real downstream uses of VLN methods. Moreover, mobile app commands provide instruction for interactive navigation, as they result in action sequences with state changes via clicking, typing, or swiping. MoTIF is the first to include feasibility annotations, containing both binary feasibility labels and fine-grained labels for why tasks are unsatisfiable. We further collect follow-up questions for ambiguous queries to enable research on task uncertainty resolution. Equipped with our dataset, we propose the new problem of feasibility prediction, in which a natural language instruction and multimodal app environment are used to predict command feasibility. MoTIF provides a more realistic app dataset as it contains many diverse environments, high-level goals, and longer action sequences than prior work. We evaluate interactive VLN methods using MoTIF, quantify the generalization ability of current approaches to new app environments, and measure the effect of task feasibility on navigation performance.
|
|
In recent years, vision-language research has shifted to study tasks which require more complex reasoning, such as interactive question answering, visual common sense reasoning, and question-answer plausibility prediction. However, the datasets used for these problems fail to capture the complexity of real inputs and multimodal environments, such as ambiguous natural language requests and diverse digital domains. We introduce Mobile app Tasks with Iterative Feedback (MoTIF), a dataset with natural language commands for the greatest number of interactive environments to date. MoTIF is the first to contain natural language requests for interactive environments that are not satisfiable, and we obtain follow-up questions on this subset to enable research on task uncertainty resolution. We perform initial feasibility classification experiments and only reach an F1 score of 37.3, verifying the need for richer vision-language representations and improved architectures to reason about task feasibility. |

|
Disentangled visual representations have largely been studied with generative models such as Variational AutoEncoders (VAEs). While prior work has focused on generative methods for disentangled representation learning, these approaches do not scale to large datasets due to current limitations of generative models. Instead, we explore regularization methods with contrastive learning, which could result in disentangled representations that are powerful enough for large scale datasets and downstream applications. However, we find that unsupervised disentanglement is difficult to achieve due to optimization and initialization sensitivity, with trade-offs in task performance. We evaluate disentanglement with downstream tasks, analyze the benefits and disadvantages of each regularization used, and discuss future directions. |
|
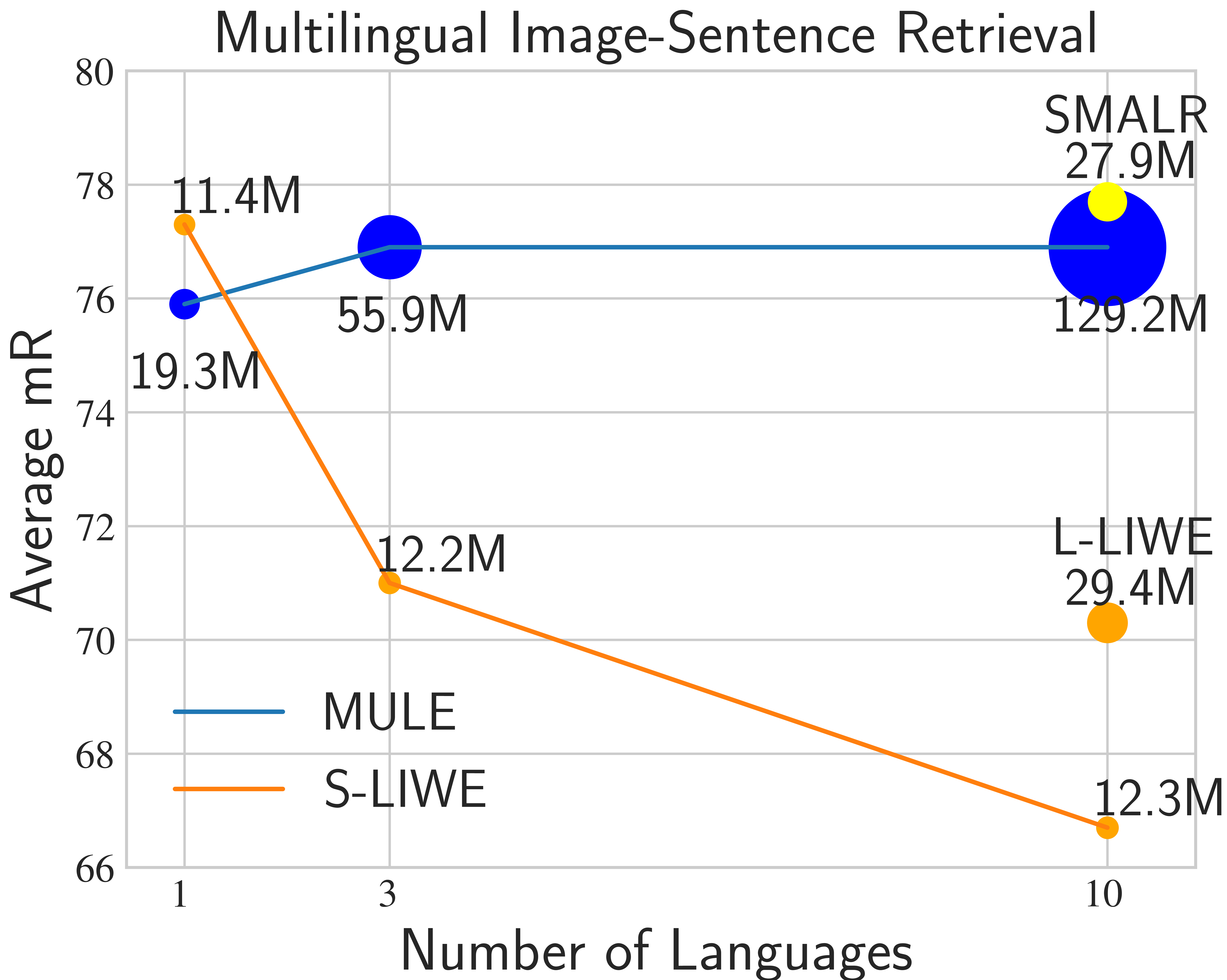
Current multilingual vision-language models either require a large number of additional parameters for each supported language, or suffer performance degradation as languages are added. In this paper, we propose a Scalable Multilingual Aligned Language Representation (SMALR) that represents many languages with few model parameters without sacrificing downstream task performance. SMALR learns a fixed size language-agnostic representation for most words in a multilingual vocabulary, keeping language-specific features for few. We use a novel masked cross-language modeling loss to align features with context from other languages. Additionally, we propose a cross-lingual consistency module that ensures predictions made for a query and its machine translation are comparable. The effectiveness of SMALR is demonstrated with ten diverse languages, over twice the number supported in vision-language tasks to date. We evaluate on multilingual image-sentence retrieval and outperform prior work by 3-4% with less than 1/5th the training parameters compared to other word embedding methods. |
|
We rigorously analyze different word embeddings, language models, and embedding augmentation steps on five common VL tasks: image-sentence retrieval, image captioning, visual question answering, phrase grounding, and text-to-clip retrieval. Our experiments provide some striking results; an average embedding language model outperforms an LSTM on retrieval-style tasks; state-of-the-art representations such as BERT perform relatively poorly on vision-language tasks. From this comprehensive set of experiments we propose a set of best practices for incorporating the language component of VL tasks. To further elevate language features, we also show that knowledge in vision-language problems can be transferred across tasks to gain performance with multi-task training. This multi-task training is applied to a new Graph Oriented Vision-Language Embedding (GrOVLE), which we adapt from Word2Vec using WordNet and an original visual-language graph built from Visual Genome, providing a ready-to-use vision-language embedding. |

|
Multispectral imaging can be used as a multimodal source to increase prediction accuracy of many machine learning algorithms by introducing additional spectral bands in data samples. This paper introduces a newly curated Multispectral Liquid 12-band (MeL12) dataset, consisting of 12 classes: eleven liquids and an "empty container" class. The usefulness of multispectral imaging in classification of liquids is demonstrated through the use of a support vector machine on MeL12 for classification of the 12 classes. The reported results are both encouraging and point to the need for additional work to improve liquid classification of harmless and dangerous liquids in high-risk environments, such as airports, concert halls, and political arenas, using multispectral imaging. |
|
|
|
 |
Third place winner of the VizWiz Grand Challenge at CVPR 2020, awarded $10K Azure Credit. Continued work in progress.
|
 |
Implemented logistic regression and perceptron algorithms by creating abstract supervised learning templates in ATS. |
 |
Compared feature representation performing VSR of the AVLetters dataset with Hu moments, Zernike moments, HOG descriptors, and LBP-TOP features. Investigated frame-level and video-level classification using an SVM classifier in SciKitLearn. |
 |
Created a multimodal machine learning model to learn the urgency of a voice message after categorizing it into four emotions: anger, fear, joy, and sadness. Used Python’s SciKitLearn and SDK libraries to apply emotion classification and unsupervised intensity regression on audio and text data. |
|
|