|
I am fortunate to be advised by Professors Kate Saenko and Bryan Plummer. I am also very grateful to be able to collaborate closely with Dr Bryan Russell at Adobe Research. My primary research interests fall under the general umbrella of multimodal learning and video understanding. |
|
Computer Vision, Video Understanding, Multimodal learning, Multimodal-LLMs |
|
|

|
Reuben Tan, Ximeng Sun, Ping Hu, Jui-hsien Wang, Hanieh Deilamsalehy, Bryan A. Plummer, Bryan Russell, Kate Saenko CVPR, 2024 Project page / Code / arXiv We propose a lightweight and self-supervised approach that introduces learnable spatiotemporal queries to adapt pretrained video-LLMs for generalizing to much longer videos. Our approach introduces a global-local video Qformer with two new modules that use the global video context to compute contextual tokens for understanding short and long video moments. We train our proposed approach on HowTo100M and demonstrate its effectiveness on zero-shot long video understanding benchmarks. |

|
Katherine Deng, Arijit Ray, Reuben Tan, Saadia Gabriel, Bryan A. Plummer, Kate Saenko ICCV Wecia, 2023 Project page / Dataset / arXiv We propose Socratis, a societal reactions bench-mark, where each image-caption (IC) pair is annotated with multiple emotions and the reasons for feeling them. Socratis contains 18K free-form reactions for 980 emotions on 2075 image-caption pairs from 5 widely-read news and image-caption (IC) datasets. We benchmark the capability of state-of-the-art multimodal large language models to generate the reasons for feeling an emotion given an IC pair. Based on a preliminary human study, we observe that humans prefer human-written reasons over 2 times more often than machine-generated ones. |
|
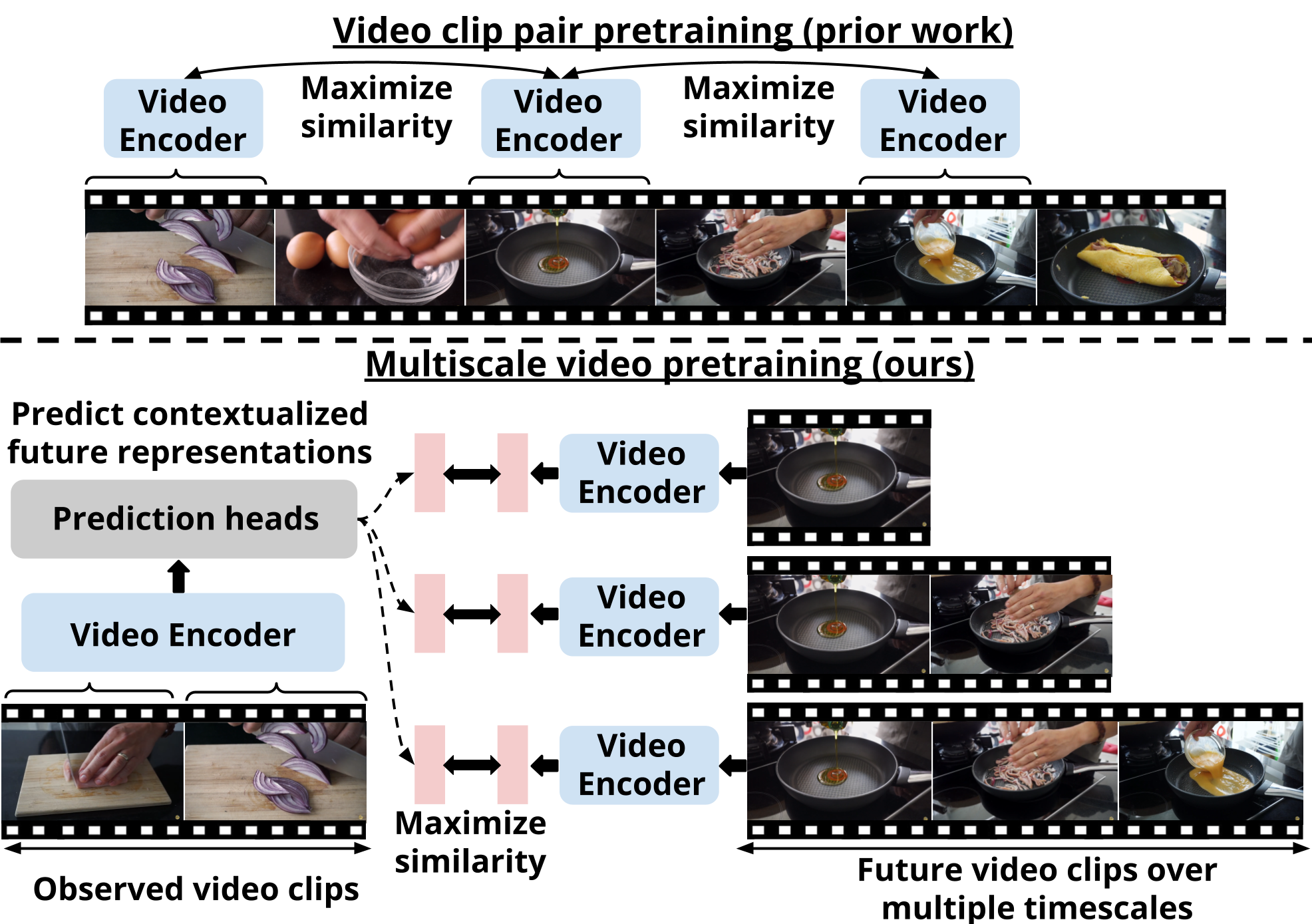
Reuben Tan, Matthias De Lange, Michael Iuzzolino, Bryan A. Plummer, Kate Saenko, Karl Ridgeway, Lorenzo Torresani Submission, 2023 Project page / Code / arXiv Long-term activity forecasting is an especially challenging research problem because it requires understanding the temporal relationships between observed actions, as well as the variability and complexity of human activities. Despite relying on strong supervision via expensive human annotations, state-of-the-art forecasting approaches often generalize poorly to unseen data. To alleviate this issue, we propose Multiscale Video Pretraining (MVP), a novel self-supervised pretraining approach that learns robust representations for forecasting by learning to predict contextualized representations of future video clips over multiple timescales. MVP is based on our observation that actions in videos have a multiscale nature, where atomic actions typically occur at a short timescale and more complex actions may span longer timescales. We compare MVP to state-of-the-art self-supervised video learning approaches on downstream long-term forecasting tasks including long-term action anticipation and video summary prediction. |
|
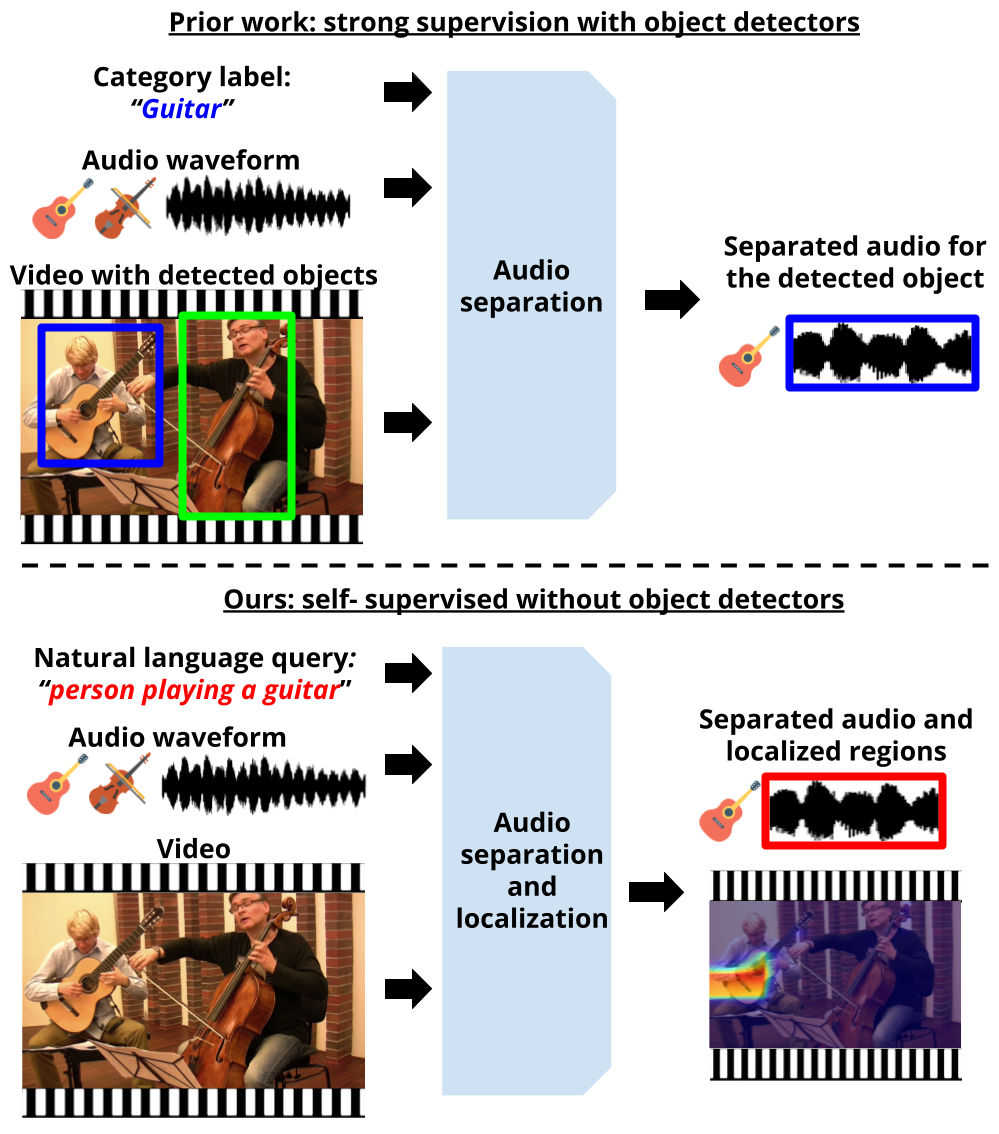
Reuben Tan, Arijit Ray, Andrea Burns, Bryan A. Plummer, Justin Salamon, Oriol Nieto, Bryan Russell, Kate Saenko CVPR, 2023 Project page / Code / arXiv We propose a self-supervised approach for learning to perform audio source separation in videos based on natural language queries, using only unlabeled video and audio pairs as training data. A key challenge in this task is learning to associate the linguistic description of a sound-emitting object to its visual features and the corresponding components of the audio waveform, all without access to annotations during training. To overcome this challenge, we adapt off-the-shelf vision-language foundation models to provide pseudo-target supervision via two novel loss functions and encourage a stronger alignment between the audio, visual and natural language modalities. During inference, our approach can separate sounds given text, video and audio input, or given text and audio input alone. |

|
Reuben Tan, Bryan A. Plummer, Kate Saenko, J.P Lewis, Avneesh Sud, Thomas Leung. ECCV, 2022 Project page / Code / arXiv Recent self-supervised approaches have used large-scale image-text datasets to learn powerful representations that transfer to many tasks without finetuning. These methods often assume that there is a one-to-one correspondence between images and their (short) captions. However, many tasks require reasoning about multiple images paired with a long text narrative, such as photos in a news article. In this work, we explore a novel setting where the goal is to learn a self-supervised visual-language representation from longer text paired with a set of photos, which we call visual summaries. In addition, unlike prior work which assumed captions have a literal relation to the image, we assume images only contain loose illustrative correspondence with the text. To explore this problem, we introduce a large-scale multimodal dataset called NewsStories containing over 31M articles, 22M images and 1M videos. |

|
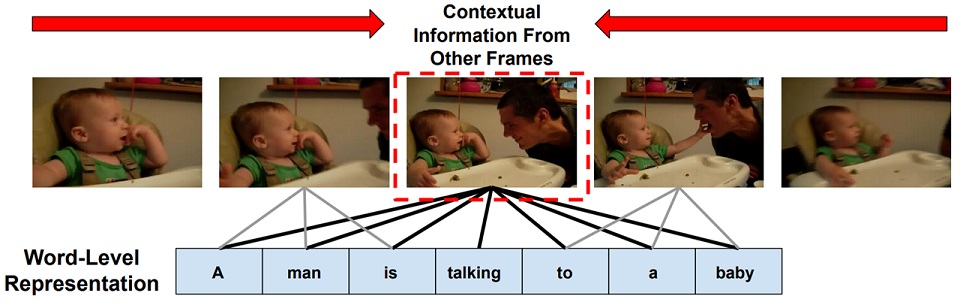
Reuben Tan, Bryan A. Plummer, Kate Saenko, Hailin Jin, Bryan Russell NeurIPS, 2021 (Spotlight) Project page / Code / arXiv We introduce the task of spatially localizing narrated interactions in videos. Key to our approach is the ability to learn to spatially localize interactions with self-supervision on a large corpus of videos with accompanying transcribed narrations. To achieve this goal, we propose a multilayer cross-modal attention network that enables effective optimization of a contrastive loss during training. We introduce a divided strategy that alternates between computing inter- and intra-modal attention across the visual and natural language modalities, which allows effective training via directly contrasting the two modalities' representations. We demonstrate the effectiveness of our approach by self-training on the HowTo100M instructional video dataset and evaluating on a newly collected dataset of localized described interactions in the YouCook2 dataset. |
|
Reuben Tan, Huijuan Xu, Kate Saenko, Bryan A. Plummer WACV, 2021 Project page / Code / arXiv The goal of weakly-supervised video moment retrieval is to localize the video segment most relevant to the given natural language query without access to temporal annotations during training. Prior strongly- and weakly-supervised approaches often leverage co-attention mechanisms to learn visual-semantic representations for localization. However, while such approaches tend to focus on identifying relationships between elements of the video and language modalities, there is less emphasis on modeling relational context between video frames given the semantic context of the query. Consequently, the above-mentioned visual-semantic representations, built upon local frame features, do not contain much contextual information. To address this limitation, we propose a Latent Graph Co-Attention Network (LoGAN) that exploits fine-grained frame-by-word interactions to reason about correspondences between all possible pairs of frames, given the semantic context of the query. |
|
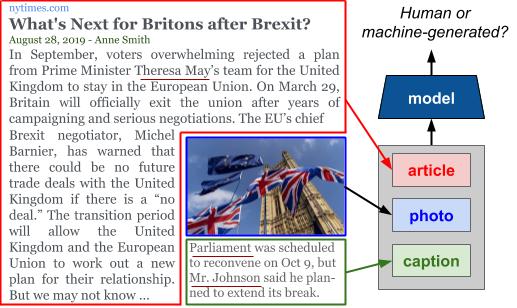
Reuben Tan, Bryan A. Plummer, Kate Saenko EMNLP, 2020 Project page / Code / arXiv Large-scale dissemination of disinformation online intended to mislead or deceive the general population is a major societal problem. Rapid progression in image, video, and natural language generative models has only exacerbated this situation and intensified our need for an effective defense mechanism. While existing approaches have been proposed to defend against neural fake news, they are generally constrained to the very limited setting where articles only have text and metadata such as the title and authors. In this paper, we introduce the more realistic and challenging task of defending against machine-generated news that also includes images and captions. To identify the possible weaknesses that adversaries can exploit, we create a NeuralNews dataset composed of 4 different types of generated articles as well as conduct a series of human user study experiments based on this dataset. In addition to the valuable insights gleaned from our user study experiments, we provide a relatively effective approach based on detecting visual-semantic inconsistencies, which will serve as an effective first line of defense and a useful reference for future work in defending against machine-generated disinformation. |
|
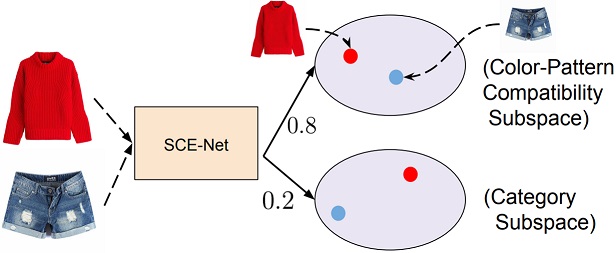
Reuben Tan, Mariya I. Vasileva, Kate Saenko, Bryan A. Plummer ICCV, 2019 Project page / Code / arXiv Many real-world tasks require models to compare images along multiple similarity conditions (e.g. similarity in color, category or shape). Existing methods often reason about these complex similarity relationships by learning condition-aware embeddings. While such embeddings aid models in learning different notions of similarity, they also limit their capability to generalize to unseen categories since they require explicit labels at test time. To address this deficiency, we propose an approach that jointly learns representations for the different similarity conditions and their contributions as a latent variable without explicit supervision. Comprehensive experiments across three datasets, Polyvore-Outfits, Maryland-Polyvore and UT-Zappos50k, demonstrate the effectiveness of our approach: our model outperforms the state-of-the-art methods, even those that are strongly supervised with pre-defined similarity conditions, on fill-in-the-blank, outfit compatibility prediction and triplet prediction tasks. Finally, we show that our model learns different visually-relevant semantic sub-spaces that allow it to generalize well to unseen categories. |
|
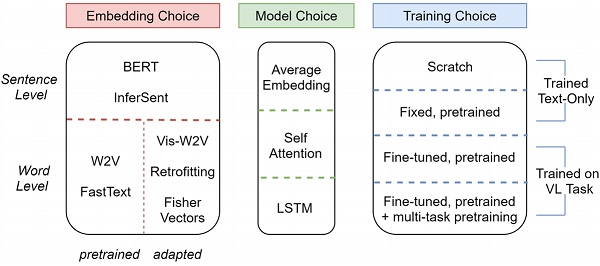
Andrea Burns, Reuben Tan, Kate Saenko, Stan Sclaroff, Bryan A. Plummer ICCV, 2019 Project page / Code / arXiv Shouldn't language and vision features be treated equally in vision-language (VL) tasks? Many VL approaches treat the language component as an afterthought, using simple language models that are either built upon fixed word embeddings trained on text-only data or are learned from scratch. We believe that language features deserve more attention, and conduct experiments which compare different word embeddings, language models, and embedding augmentation steps on five common VL tasks: image-sentence retrieval, image captioning, visual question answering, phrase grounding, and text-to-clip retrieval. Our experiments provide some striking results; an average embedding language model outperforms an LSTM on retrieval-style tasks; state-of-the-art representations such as BERT perform relatively poorly on vision-language tasks. From this comprehensive set of experiments we propose a set of best practices for incorporating the language component of VL tasks. To further elevate language features, we also show that knowledge in vision-language problems can be transferred across tasks to gain performance with multi-task training. This multi-task training is applied to a new Graph Oriented Vision-Language Embedding (GrOVLE), which we adapt from Word2Vec using WordNet and an original visual-language graph built from Visual Genome. |