|
I interned at Amazon working with Javier Romero, Timo Bolkart, Ming C. Lin and Raja Bala during the Summer of 2021. I interned at Apple AI Research during the 2019 and 2020 Summers where I worked with Dr. Barry-John Theobald and Dr. Nicholas Apostoloff. In 2018 I was a Spring/Summer intern at the NEC-Labs Media Analytics Department, where I worked with Prof. Manmohan Chandraker and Dr. Samuel Schulter. I graduated from Georgia Tech in Fall 2017 with a M.Sc. in Computer Science specializing in Machine Learning, advised by Prof. James Rehg at the Center for Behavioral Imaging.
nruiz9 [at] bu.edu | CV | Google Scholar | GitHub | LinkedIn |

|
|
Currently, my main interests include generative models, diffusion models, personalization of generative models, simulation and beneficial adversarial attacks. |
|
|

|
We present a new approach for personalization of text-to-image diffusion models. Given few-shot inputs of a subject, we fine-tune a pretrained text-to-image model to bind a unique identifier with that specific subject such that we cansynthesize fully-novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in diverse scenes, poses, views, and lighting conditions that do not appear in the reference images. We apply our technique to several previously-unassailable tasks, including subject recontextualization, text-guided view synthesis, appearance modification, and artistic rendering (all while preserving the subject's key features). |

|
We present Counterfactual Simulation Testing, a counterfactual framework that allows us to study the robustness of neural networks with respect to some of these naturalistic variations by building realistic synthetic scenes that allow us to ask counterfactual questions to the models, ultimately providing answers to questions such as "Would your classification still be correct if the object were viewed from the top?". Our method allows for a fair comparison of the robustness of recently released, state-of-the-art CNNs and Transformers, with respect to these naturalistic variations. Among other interesting differences between these classes of architectures, we find evidence for differences in performance with respect to object viewpoint, object scale and occlusions. We also release our large simulated dataset with more than 272,000 images of 92 objects under 27 lighting environments. |
|
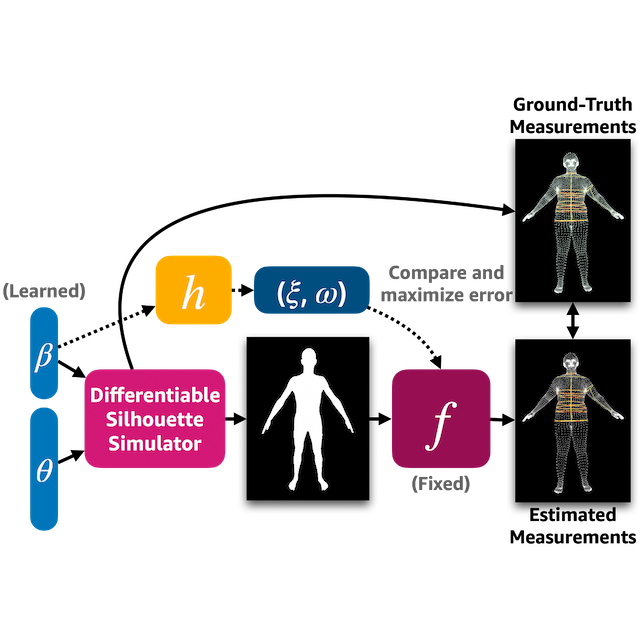
We propose a method to generate adaptive data to test and train a human body measurement estimation model in an adversarial manner by searching the latent space of a body simulator for challenging bodies. We present a state-of-the-art human body measurement estimation network that accurately predicts measurements of human bodies given only frontal and profile silhouette images, with applications to fashion and health. Finally, we release BodyM, the first challenging, large-scale dataset of photo silhouettes and body measurements of real human subjects, to further promote research in this area. |

|
We propose a framework for learning how to test machine learning models using simulators in an adversarial manner in order to find weaknesses in the models before deploying them in critical scenarios. We apply this method in a face recognition scenario. Using our proposed method, we can find adversarial faces that fool contemporary face recognition models. This demonstrates the fact that these models have weaknesses that are not measured by commonly used validation datasets. We hypothesize that this type of adversarial examples are not isolated, but usually lie in connected regions in the latent space of the simulator. We present a method to find these adversarial regions. |
|
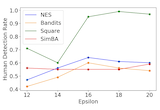
Through examining and measuring both the effectiveness of recent popular black-box attacks in the face recognition setting and their corresponding human perceptibility through survey data, we demonstrate the trade-offs in perceptibility that occur as attacks become more aggressive. We also show how the norm and other metrics do not correlate with human perceptibility in a linear fashion, thus making these norms suboptimal at measuring adversarial attack perceptibility. We argue that some attacks seem very effective when evaluated using Lp norms, but are too perceptible and thus harder to use in the real world. |

|
We present MorphGAN, a powerful GAN that can control the head pose and facial expression of a face image. MorphGAN can generalize to unseen identities (one-shot) and generates realistic outputs that conserve the input identity. We use this simulator to generate new images to test the robustness of a facial recognition deep network with respect to pose and expression, without the need to collect new test data. Aditionally, we show that the generated images can be used to augment small datasets of faces with new poses and expressions to improve recognition accuracy. |

|
We are the first to attack image translation systems in a black-box scenario. Our novel algorithm "learning universal perturbations" (LUP) significantly reduces the number of queries needed for black-box attacks by leaking and exploiting information from the deep network. Our attacks can be used to protect images from manipulation and to prevent deepfake generation in the real world. |
|
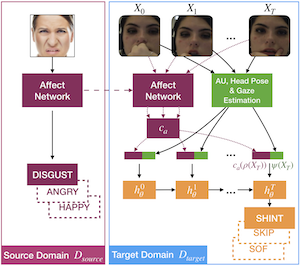
In order to improve behavior prediction and behavior understanding of students using an Intelligent Tutoring System, we present a novel instance of affect transfer learning that leverages a large affect recognition dataset. |

|
We present a method for disrupting the generation of deepfakes by generating adversarial attacks for image translation networks. We present the first instance of attacks against conditional image translation networks. Our attacks transfer across different conditioning classes. We also present the first instance of adversarial training for generative adversarial networks as a first step towards robust image translation networks. |

|
We present the most advanced video attention detection method to-date. By leveraging our new large video dataset of gaze behavior and a new neural network architecture we achieve state-of-the-art performance on three gaze following datasets and compelling real-world performance. |

|
We propose a framework to train a machine learning model by optimally sampling synthetic data. Our algorithm learns parameters of a simulation engine to generate training data for a machine learning model in order to maximize performance. We apply this algorithm to semantic segmentation for traffic scenes and evaluate on both on simulated and real data. |

|
We are the first to tackle the generalized visual attention prediction problem, which consists in predicting the 3D gaze vector, attention heatmaps inside of the image frame and whether the subject is looking inside or outside of the image. To this end, we jointly model gaze and scene saliency using a neural network architecture trained on three heterogeneous datasets. |

|
By using a deep network trained with a binned pose classification loss and a pose regression loss on a large dataset we obtain state-of-the-art head pose estimation results on several popular benchmarks. Our head pose estimation models generalize to different domains and work on low-resolution images. We release an open-source software package with pre-trained models that can be used directly on images and video. |

|
We present a framework that, given an instructional video, can localize atomic action segments and align them to the appropriate instructional step using object recognition and natural language. |

|
We introduce the Pose-Implicit CNN, a novel deep learning architecture that predicts eye contact while implicitly estimating the head pose. The model is trained on a dataset comprising 22 hours of 156 play session videos from over 100 children, half of whom are diagnosed with Autism Spectrum Disorder. |
|
In order to help the wider scientific community, we release a pre-trained deep learning face detector that is easy to download and use on images and video. |
|
|
 |
Real-time object detection on Android using the YOLO network with TensorFlow. |
|
|