|
I am a Ph.D. student at Boston University and am very lucky to be co-advised by Professor Kate Saenko and Professor Bryan Plummer. Prior to my Ph.D., I was an AI Resident on the Perception Team at Google Research, where I spent two amazing years working with Dr. Dilip Krishnan, Dr. Ce Liu, Professor Mike Mozer, and many others. Prior to that, I spent time on the ML team at Apple, and worked at a startup called Turi. During my Ph.D., I have also interned at Meta, most recently at Meta Superintelligence Labs on the Segment Anything team. I got my Bachelor's degree in Computer Science from Dartmouth College. Email / CV / Google Scholar / Twitter |

|
|
I'm broadly interested in machine learning and computer vision, and am particularly interested in learning compact but semantically rich representations of our world. To me, this can mean finding better/cheaper/faster ways of training representations which generalize well to new distributions. |
|
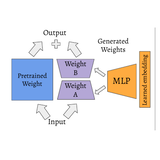
Piotr Teterwak, Kate Saenko, Bryan A. Plummer, Ser-Nam Lim Workshop on Efficient Deep Learning for Computer Vision, CVPR, 2026 OP-LoRA improves low-rank adapter fine-tuning by using a small temporary MLP to predict the adapter weights during training, yielding better optimization without any added inference cost. |

|
Piotr Teterwak, Kuniaki Saito, Theodoros Tsiligkaridis, Bryan A. Plummer, Kate Saenko ICLR, 2025 We ask whether gains in domain generalization come from better methods or just stronger pretrained models, and propose the Alignment Hypothesis: downstream performance is high if and only if image and class-label-text embeddings are well aligned—current methods still struggle on data far from the pretraining distribution. |
|
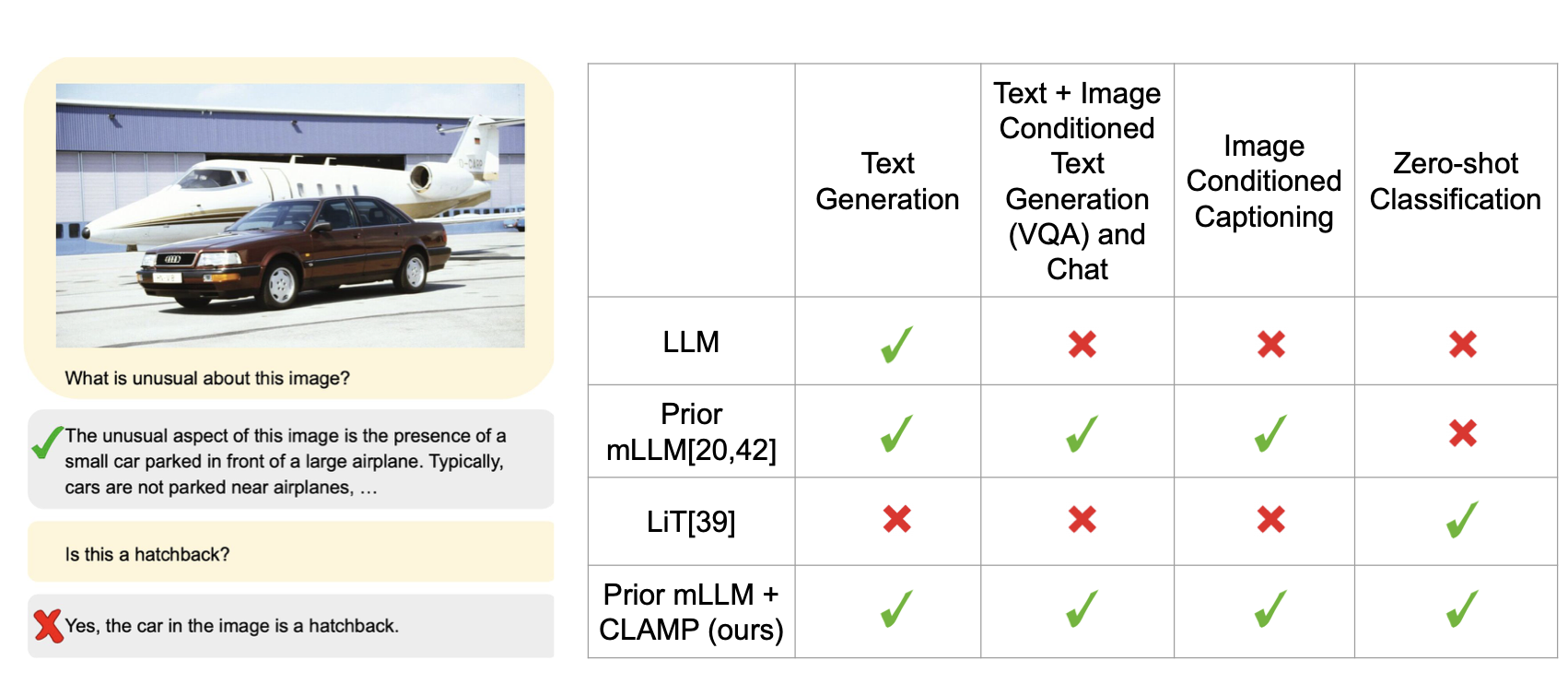
Piotr Teterwak, Ximeng Sun, Bryan A. Plummer, Kate Saenko, Ser-Nam Lim arXiv, 2023 We adapt large language models for image classification by fine-tuning them with the same contrastive image-caption objective as CLIP, achieving strong classification accuracy. |
|
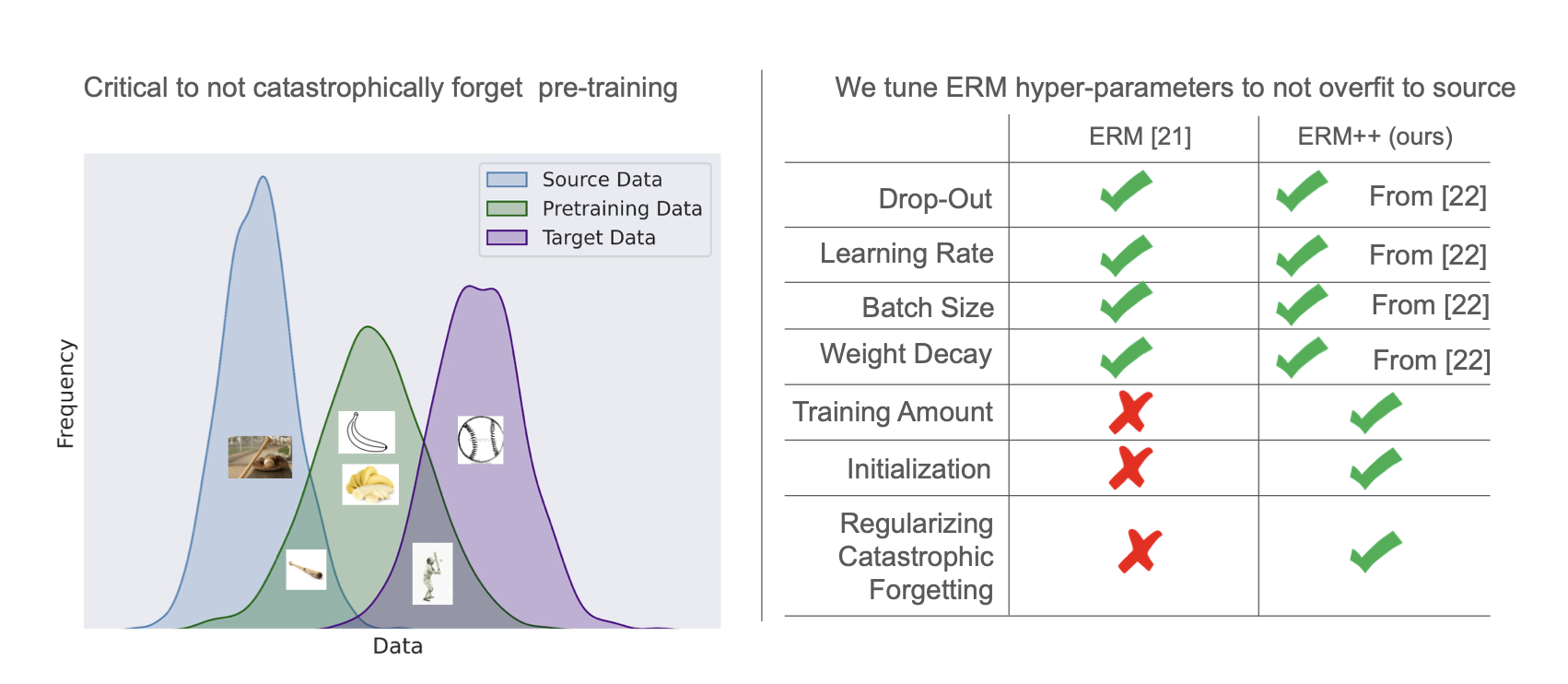
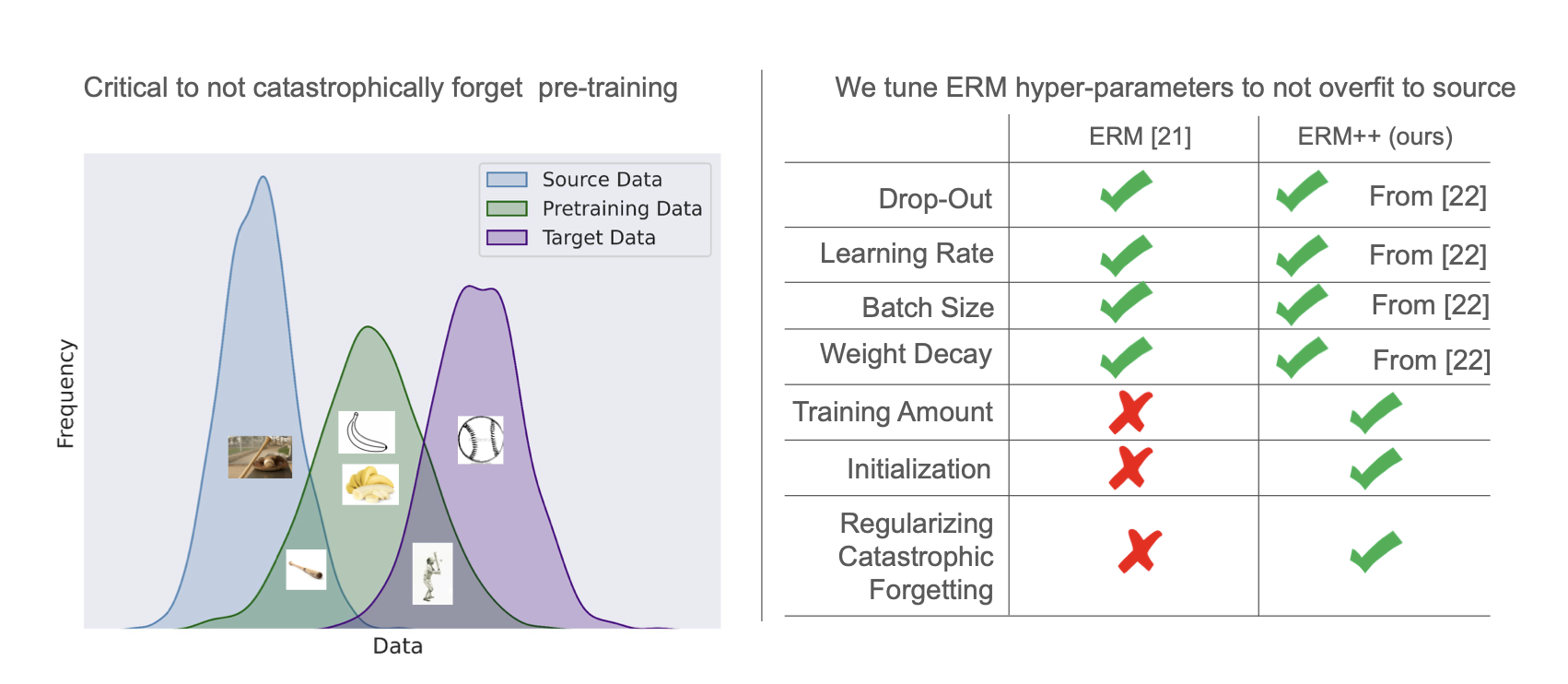
Piotr Teterwak, Kuniaki Saito, Theodoros Tsiligkaridis, Bryan A. Plummer, Kate Saenko WACV, 2025 A stronger baseline for domain generalization that shows plain Empirical Risk Minimization, with careful attention to data utilization, initialization, and regularization, outperforms many specialized methods without added complexity. |
|
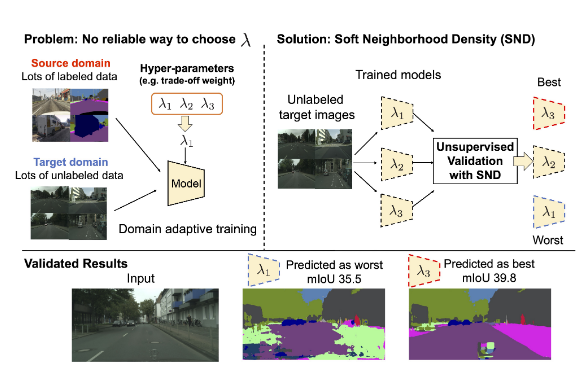
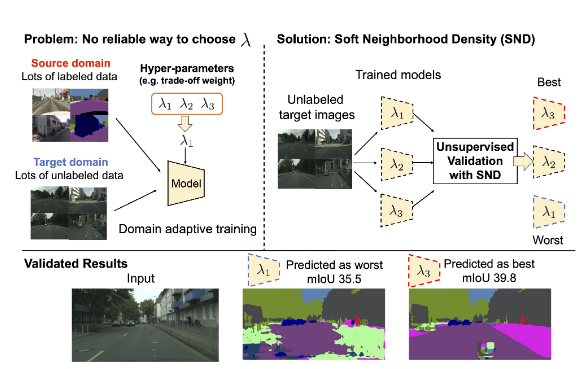
Kuniaki Saito, Donghyun Kim, Piotr Teterwak, Stan Sclaroff, Trevor Darrell, Kate Saenko ICCV, 2021 How to determine what hyperparameters to use for unsupervised domain adaptation, without cheating. |
|
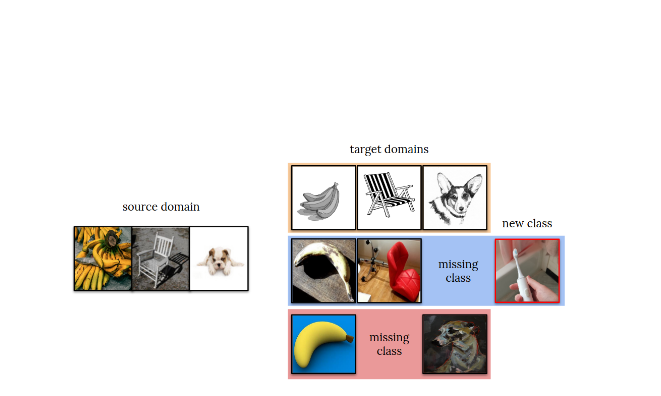
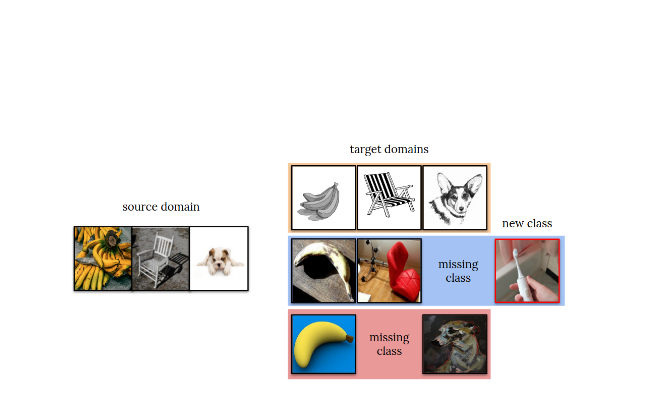
Dina Bashkirova*, Dan Hendrycks*, Donghyun Kim*, Samarth Mishra*, Kate Saenko*, Kuniaki Saito*, Piotr Teterwak* (equal contribution), Ben Usman* NeurIPS Competition Track, 2021 This challenge tests how well models can (1) adapt to several distribution shifts and (2) detect unknown unknowns. |
 
|
Piotr Teterwak, Chiyuan Zhang, Dilip Krishnan, Michael C. Mozer ICML, 2021 Understanding what information is preserved in classifier logits by training GAN-based inversion model. Surprisingly, we can reconstruct images well, though it depends on architecture and optimization procedure. |
 
|
Richard Strong Bowen, Huiwen Chang, Charles Herrmann, Piotr Teterwak, Ramin Zabih CVPR, 2021 Improving image extrapolation for objects. |
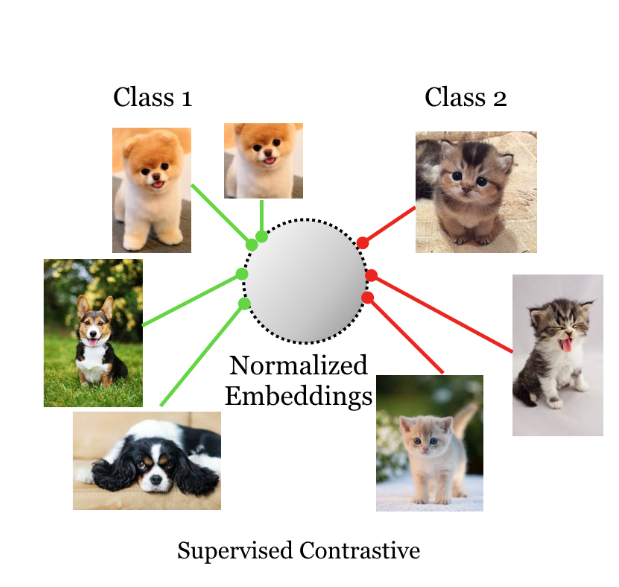
|
Prannay Khosla*, Piotr Teterwak* (equal contribution), Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, Dilip Krishnan NeurIPS, 2020. 8000+ citations. arXiv A new loss function to train supervised deep networks, based on contrastive learning. Our new loss performs significantly better than cross-entropy across a range of architectures and data augmentations. |
 
|
Piotr Teterwak, Aaron Sarna, Dilip Krishnan, Aaron Maschinot, David Belanger, Ce Liu, William T. Freeman ICCV 2019 Project Page Pretrained Models and Tutorial We adapt GAN's for the image extrapolation problem, and use a novel feature conditioning to improve results. |
|
|
|
NSF GRFP Honorable Mention Dean's Fellowship |
|
Template from Jon Barron's really cool website, |