Video-based Student Engagement Measurement Datasets 

|
Citation If you use our datasets, please cite this work: N. Ruiz, H. Yu, D. Allessio, M. Jalal, A. Joshi, T. Murray, J. Magee, J. Whitehill, V. Ablavsky, I. Arroyo, B. Woolf, S. Sclaroff, M. Betke. "Leveraging Affect Transfer Learning for Behavior Prediction in an Intelligent Tutoring System" FG, 2021. pdf K. Deglado, J. M. Origgi, T. Hansapoor, H. Yu, D. Allessio, I. Arroyo, W. Lee, M. Betke, B. Woolf, S. A. Bargal. "Student Engagement Dataset" ICCVW, 2021. pdf Contact Please contact Hao Yu if you have any questions. |
Datasets
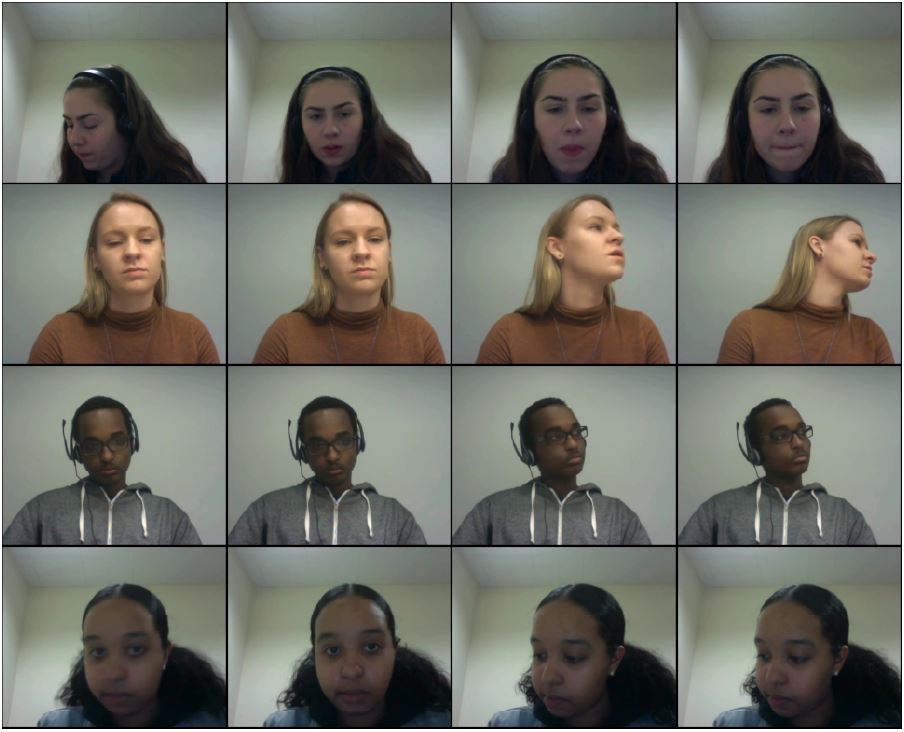
The dataset was collected by the University of Massachusetts Amherst. Students who participated in this dataset
were recorded while solving math problems on MathSpring. Each student had a webcam in front of them and each
were provided with a piece of paper to the right of the computer for notes. The students were recorded while solving
the problems and each video corresponds to a single student solving a single problem. The dataset was annotated by the effort on a video level (FG paper),
and a subset of the dataset was annotated by the level of student engagement on a frame level (ICCVW paper).
Data has been collected from participants with consent.
FG Video Effort Annotations
#Classes: 7
#Participants - Total: 54
Annotations: Video-level
This dataset consists of approximately 2749 video clips divided between seven classes (attempt, give up, guess, not read, solve with hint, skip, solve on the first attempt) for 54 different students. Several students participated in multiple sessions. In total, 68 student sessions were recorded. We divide each student's video session into shorter video clips, where each segment is associated with an individual math problem. Each math problem video clip has an associated problem outcome. This problem outcome is automatically labeled by the software using a rule-based algorithm.
This dataset consists of approximately 2749 video clips divided between seven classes (attempt, give up, guess, not read, solve with hint, skip, solve on the first attempt) for 54 different students. Several students participated in multiple sessions. In total, 68 student sessions were recorded. We divide each student's video session into shorter video clips, where each segment is associated with an individual math problem. Each math problem video clip has an associated problem outcome. This problem outcome is automatically labeled by the software using a rule-based algorithm.
ICCVW Frame Engagement Annotations
#Classes: 3
#Participants - Total: 19
Annotations: Frame-level
This subset consists of approximately 19K frames divided between three classes (looking at screen, looking at paper, wandering) for 19 different students. For the frame-level annotations, videos of 19 participants were sampled at one FPS, which gave us a total 18,721 frames. In the raw distribution of this data, the Screen class includes 14 times more samples than the Wander class, and three times more than the Paper class. The Paper class includes 4,655 frames, the Screen class includes 13,483 frames, and the Wander class includes 583 frames for a total of 18,721 frames. We also include a more balanced version of this dataset by removing similar samples for each class. This dataset is more equally distributed and contains 638 samples for the Paper class, 826 samples for the Screen class, and 509 samples for the Wander class for a total of 1,973 samples. In order to test the model on different data, we only sampled three students out of the original 19 for our test set.
This subset consists of approximately 19K frames divided between three classes (looking at screen, looking at paper, wandering) for 19 different students. For the frame-level annotations, videos of 19 participants were sampled at one FPS, which gave us a total 18,721 frames. In the raw distribution of this data, the Screen class includes 14 times more samples than the Wander class, and three times more than the Paper class. The Paper class includes 4,655 frames, the Screen class includes 13,483 frames, and the Wander class includes 583 frames for a total of 18,721 frames. We also include a more balanced version of this dataset by removing similar samples for each class. This dataset is more equally distributed and contains 638 samples for the Paper class, 826 samples for the Screen class, and 509 samples for the Wander class for a total of 1,973 samples. In order to test the model on different data, we only sampled three students out of the original 19 for our test set.
To obtain the datasets, please fill out this form
Copyright Notice: These materials are presented to ensure timely dissemination of scholarly and technical work, and for academic research purpose only. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.