Audio-Visual Separation
VAST can be used on raw videos to perform denoising of background sounds and localization of the input audio. The goal is to remove sounds of non-visible objects.
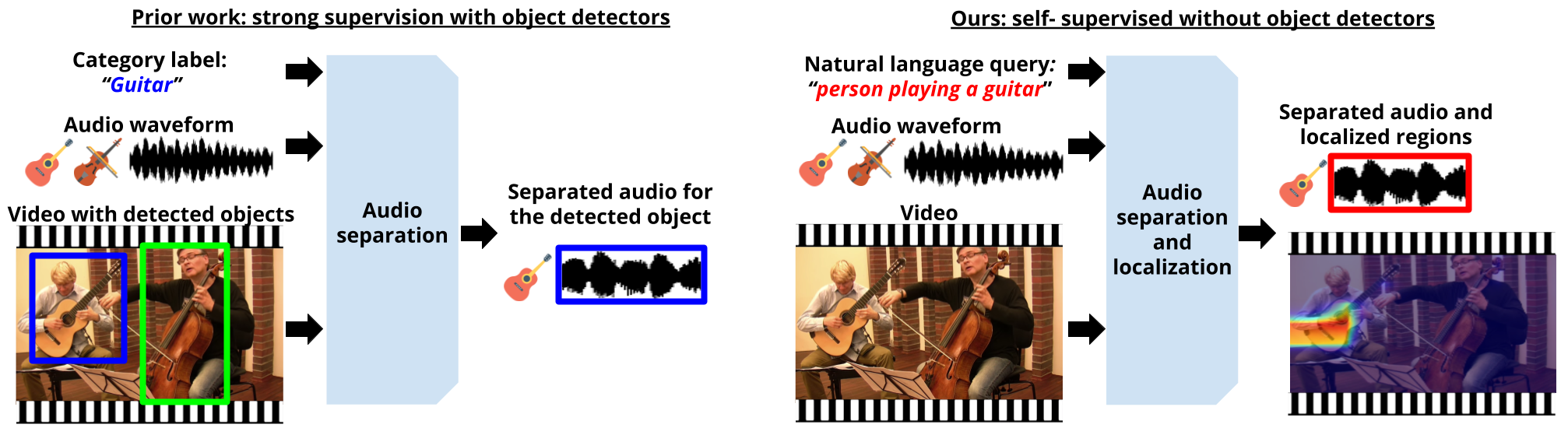
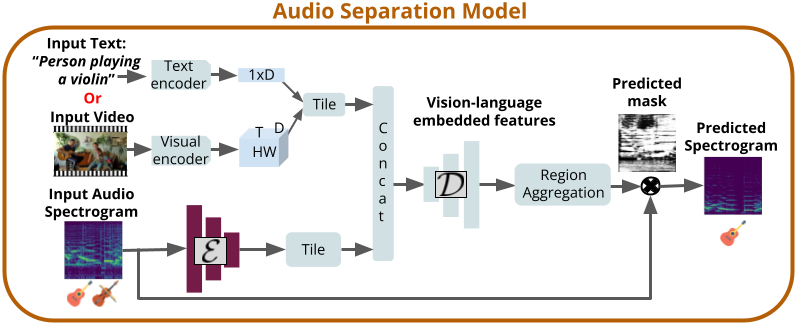
We propose a self-supervised approach VAST: Video-Audio Separation through Text for learning to perform audio source separation in videos based on natural language queries, using only unlabeled video and audio pairs as training data. A key challenge in this task is learning to associate the linguistic description of a sound-emitting object to its visual features and the corresponding components of the audio waveform, all without access to annotations during training.
To overcome this challenge, we adapt off-the-shelf vision-language foundation models to provide pseudo-target supervision via two novel loss functions and encourage a stronger alignment between the audio, visual and natural language modalities. During inference, our approach can separate sounds given text, video and audio input, or given text and audio input alone. We demonstrate the effectiveness of our self-supervised approach on three audio-visual separation datasets, including MUSIC, SOLOS and AudioSet, where we outperform state-of-the-art strongly supervised approaches despite not using object detectors or text labels during training.
We propose a unified approach that can jointly perform audio-visual and audio-text source separation. Existing audio-visual methods do not generalize to natural language queries due to their dependence on discrete object class labels. Furthermore, they assume the presence of prior knowledge of sounding objects and their locations in the form of preextracted bounding boxes during training and inference. To alleviate this dependence, our VAST approach leverages large vision-language foundation models to provide pseudo supervision.
VAST can be used on raw videos to perform denoising of background sounds and localization of the input audio. The goal is to remove sounds of non-visible objects.
Despite not training with ground-truth text annotations, as a byproduct of our training approach, VAST can also separate audio sources based on natural language queries.
Here are some relevant work that are used as baselines in our experiments.
Sound of Pixels introduces the self-supervised mix-and-separate pretraining method to train an audio-visual separation model without ground-truth audio source annotations.
Sound of Motions leverages motion cues such as optical flow to improve audio-visual separation.
Co-Separating Sounds of Visual Objects introduces the idea to replace convolutional grid representations with object bounding boxes and their representations for audio-visual source separation.
Visual Scene Graphs for Audio Source Separation proposes to use a spatiotemporal scene graph over detected objects to aggregate contextual information between regions for more effective audio separation.
@InProceedings{TanAVSet2023,
author = {Reuben Tan and Arijit Ray and Andrea Burns and Bryan A. Plummer and Justin Salamon and Oriol Nieto and Bryan Russell and Kate Saenko},
title = {Language-Guided Audio-Visual Source Separation via Trimodal Consistency},
journal = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023},
}