

Next: The traditional approach to
Up: Analysis of Bernstein's Factorization
Previous: Bibliography
Using off-the-shelf hardware for the circuit
approach
In subsections 5.3-5.5 we were concerned
primarily with custom-produced hardware, in accordance with the focus
on throughput cost. In practice, however, we are often concerned about
solving a small number of factorization problems. In this case, it may
be preferable to use off-the-shelf components (especially if they can
be dismantled and reused, or if discreteness is desired).
Tables 2-4 in
Section 5.5 contain the parameters and cost estimates for
off-the-shelf hardware, using the following scheme. FPGA chips are
connected in a two-dimensional grid, where each chip holds a block of
mesh nodes. The FPGA we consider is the Altera Stratix EP1S25F1020C7,
which is expected to cost about $150 in large quantities in
mid-2003. It contains 2Mbit of DRAM and 25660 ``logic elements''
that consist each of a single-bit register and some configurable
logic. Since on-chip DRAM is scant, we connect each FPGA to several
DRAM chips. The FPGA has 706 I/O pins that can provide about
70Gbit/sec of bandwidth to the DRAM chips (we can fully utilize this
bandwidth by ``swapping'' large continuous chunks into the on-FPGA
DRAM; the algorithm allows efficient scheduling). These I/O pins can
also be used for communicating with neighbouring FPGAs at an aggregate
bandwidth of 280Gbit/sec.
The parameters given in Table 2 are normalized,
such that one LE is considered to occupy 1 area unit, and thus
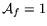 . We make the crude assumption that each LE provides the
equivalent of 20 logic transistors in our custom design, so
. We make the crude assumption that each LE provides the
equivalent of 20 logic transistors in our custom design, so
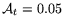 . Every FPGA chip is considered a ``wafer'' for the
purpose of calculation, so
. Every FPGA chip is considered a ``wafer'' for the
purpose of calculation, so
 . Since DRAM is located
outside the FGPA chips,
. Since DRAM is located
outside the FGPA chips, 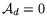 but
but
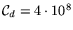 , assuming
$320 per gigabyte of DRAM.
, assuming
$320 per gigabyte of DRAM.
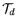 and
and
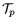 are set according to
available bandwidth. For
are set according to
available bandwidth. For
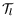 we assume that on average an LE
switches at 700MHz.
we assume that on average an LE
switches at 700MHz. 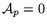 , but we need to verify that the derived
, but we need to verify that the derived
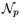 is at most 706 (fortunately this holds for all our parameter
choices).
As can be seen from the tables, the FPGA-based devices are
significantly less efficient than both the custom designs and properly
parallelized PC-based implementation. Thus they appear unattractive.
is at most 706 (fortunately this holds for all our parameter
choices).
As can be seen from the tables, the FPGA-based devices are
significantly less efficient than both the custom designs and properly
parallelized PC-based implementation. Thus they appear unattractive.
Next: The traditional approach to
Up: Analysis of Bernstein's Factorization
Previous: Bibliography