In this section we extrapolate current factoring knowledge to come up
with reasonable estimates for the sizes of the matrix that would have
to be processed for the factorization of a 1024-bit composite when using
ordinary relation collection (cf. 2.6), and using slower
relation collection according to matrix exponent as used in
circuit-NFS.
For the latter (smaller sized) matrix we consider how expensive it would
be to build the mesh-sorting-based matrix-by-vector multiplication circuit
proposed in [1] using custom-built hardware and we estimate how much
time
the matrix step would take on the resulting device. We then propose
an alternative mesh-based matrix-by-vector multiplication circuit
and estimate its performance for both matrices, for custom-built and
off-the-shelf hardware.
Throughout this section we are interested mainly in assessing
feasibility, for the purpose of evaluating the security
implications. Our assumptions will be somewhat optimistic, but we
believe that the designs are fundamentally sound and give realistic
indications of feasibility using technology that is available in the
present or in the near future.
5.1. Matrix sizes.
For the factorization of RSA-512 the matrix had about 6.7 million columns
and
average column density about 63 [3]. There is no doubt
that this matrix is considerably smaller than a matrix that would have
resulted from ordinary relation collection as defined in 2.6,
cf. Remark 3.7.
Nevertheless, we make the optimistic assumption
that this is the size that would result from ordinary relation collection.
Combining this figure with the
matrix size growth rate
(cf. 2.6) we find
(cf. 2.1).
Including the effect of the it is estimated that an optimal
1024-bit matrix would contain about columns. We
optimistically assume an average column density of about .
We refer to this matrix as the ``large'' matrix.
Correcting this matrix size for the
matrix size
growth rate for matrix exponent (cf. 2.6) we find
We arrive at an estimate of about
columns for the
circuit-NFS 1024-bit matrix. We again, optimistically, assume that the
average column density is about .
We refer to this matrix as the ``small'' matrix.
5.2. Estimated relation collection cost.
Relation collection for RSA-512 could have been done in about 8 years
on a 1GHz PC [3]. Since
we estimate that generating the large matrix would require about a year
on about 30 million 1GHz PCs with large memories (or more PC-time but
less memory when using alternative smoothness tests - keep in mind,
though, that it may be possible to achieve the same operation count
using different hardware, as rightly noted in [1] and
speculated in [12, 2.4.7]). With
it follows that generating the smaller matrix would require about 5 times
the above effort. Neither computation is infeasible. But, it can be argued that
1024-bit RSA moduli provide a reasonable level of security just based on
the operation count of the relation collection step.
5.3. Processing the ``small'' matrix using Bernstein's circuits.
We estimate the size of the circuit required to implement the mesh
circuit of [1] when the NFS parameters are optimized for the
throughput cost function and 1024-bit composites. We then derive a
rough prediction of the associated costs when the mesh is implemented
by custom hardware using current VLSI technology. In this subsection
we use the circuit exactly as described in [1]; the next
subsections will make several improvements, including those listed as
future plans in [1].
In [1], the algorithm used for finding dependencies among the
columns of is Wiedemann's original algorithm [18],
which is a special case of block Wiedemann with blocking factor =1
(cf. 2.5). In the first stage (inner product
computation), we are given the sparse
matrix and some
pair of vectors
and wish to calculate
for
. The polynomial evaluation stage is slightly
different, but the designs given below can be easily adapted so we
will not discuss it explicitly.
The mesh consists of nodes, where
(cf. 3.1). By assumption,
and
so we may choose . To execute the
sorting-based algorithm, each node consists mainly of 3 registers of
bits each, a
26-bit compare-exchange element (in at least half of the nodes), and
some logic for tracking the current stage of the algorithm. Input,
namely the nonzero elements of and the initial vector , is
loaded just once so this can be done serially. The mesh computes the
vectors
by repeated matrix-by-vector multiplication, and
following each such multiplication it calculates the inner product
and outputs this single bit.
In standard CMOS VLSI design, a single-bit register (i.e., a D-type
edge-triggered flip-flop) requires about 8 transistors, which amounts
to 624 transistors per node. To account for the logic and additional
overheads such as a clock distribution network, we shall assume an
average of 2000 transistors per node for a total of
transistors in the mesh.
As a representative of current technology available on large scale
we consider Intel's latest Pentium processor, the Pentium 4
``Northwood'' (0.13
feature size process). A single
Northwood chip (inclusive of its on-board L2 cache) contains
transistors, and can be manufactured in dies of
size
on wafers of diameter 300mm,
i.e., about 530 chips per wafer when disregarding defects.
The 1.6GHz variant
is currently sold at $140 in retail channels. By transistor count,
the complete mesh would require about
Northwood-sized dies or about wafers. Using the above per-chip
price figure naively, the construction cost is about $20M.
Alternatively, assuming a wafer cost of about $5,000
we get a construction cost of roughly $1.4M,
and the initial costs (e.g., mask creation) are under $1M.
The matter of inter-chip communication is problematic. The mesh as a
whole needs very few external lines (serial input, 1-bit output,
clock, and power). However, a chip consisting of nodes has
nodes on its edges, and each of these needs two 26-bit
bidirectional links with its neighbor on an adjacent chip, for a total
of about
connections. Moreover, such
connections typically do not support the full 1GHz clock rate, so to
achieve the necessary bandwidth we will need about 4 times as many
connections: . While standard wiring technology cannot provide
such enormous density, the following scheme seems plausible. Emerging
``flip-chip'' technologies allow direct connections between chips that
are placed face-to-face, at a density of 277 connections per mm
(i.e., 60s array pitch). We cut each wafer into the shape of a
cross, and arrange the wafers in a two-dimensional grid with the arms
of adjacent wafers in full overlap. The central square of each
cross-shaped wafer contains mesh nodes, and the arms are dedicated to
inter-wafer connections. Simple calculation shows that with the above
connection density, if 40% of the (uncut) wafer area is used for mesh
nodes then there is sufficient room left for the connection pads and
associated circuitry. This disregards the issues of delays (mesh edges
that cross wafer boundaries are realized by longer wires and are thus
slower than the rest), and of the defects which are bound to occur. To
address these, adaptation of the algorithm is needed. Assuming the
algorithmic issues are surmountable, the inter-wafer communication
entails a cost increase by a factor of about 3, to $4.1M.
According to [1, Section 4], a matrix-by-vector multiplication
consists of, essentially, three sort operations on the
mesh. Each sort operation takes steps, where each step consists
of a compare-exchange operation between 26-bit registers of adjacent
nodes. Thus, multiplication requires
steps. Assuming that each step takes a single clock cycle at a
1GHz clock rate, we get a throughput of multiplications per
second.
Basically, Wiedemann's algorithm requires multiplications. Alas,
the use of blocking factor entails some additional costs. First,
the number of multiplications roughly doubles due to the possibility
of failure (cf. 2.5). Moreover, the algorithm will yield
a single vector from the kernel of , whereas the Number Field Sieve
requires several linearly independent kernel elements: half of these
yield a trivial congruence (c.f. 2.2), and moreover certain
NFS optimizations necessitate discarding most of the vectors. In
RSA-512, a total of about 10 kernel vectors were needed. Fortunately,
getting additional vectors is likely to be cheaper than getting the
first one (this is implicit in
[18, Algorithm 1]). Overall, we expect the number of
multiplications to be roughly
. Thus, the expected total running time is roughly
seconds, or 14 days. The
throughput cost is thus
.
If we increase the blocking factor from 1 to over 32 and handle the
multiplication chains sequentially on a single mesh, then only
multiplications are needed ([1] considers this but claims that it
will not change the cost of computation; that is true only up to
constant factors). In this case the time decreases to 50 hours, and
the throughput cost decreases to
.
Heat dissipation (i.e., power consumption)
may limit the node density and clock rate of the device, and needs to
be analysed. Note however that this limitation is technological rather
than theoretical, since in principle the mesh sorting algorithm can be
efficiently implemented using reversible gates and arbitrarily low
heat dissipation.
5.4. A routing-based circuit.
The above analysis refers to the mesh circuit described in [1],
which relies on the novel use of mesh sorting for matrix-by-vector
multiplication. We now present an alternative design, based on mesh
routing. This design performs a single routing operation per
multiplication, compared to three sorting operations (where even a
single sorting operation is slower than routing). The resulting design
has a reduced cost, improved fault tolerance and very simple local
control. Moreover, its inherent flexibility allows further
improvements, as discussed in the next section.
The basic design is as follows.
For simplicity assume that each of the columns of the matrix has
weight exactly (here ), and that the nonzero elements of
are uniformly distributed (both assumptions can be easily
relaxed).
Let
. We divide the mesh into
blocks of size
. Let denote the
-th block in row-major order (
), and let
denote the node in the upper left corner of . We say
that is the target of the value . Each node holds
two
-bit values, and . Each target node
also contains a single-bit value . For repeated
multiplication of and , the mesh is initialized as follows:
the -th entry of is loaded into , and the row indices
of the nonzero elements in column
of are
stored (in arbitrary order) in the of the nodes in
. Each multiplication is performed thus:
For all , broadcast the value of from to the
rest of the nodes in (this can be accomplished in
steps).
For all and every node in : if then
,
else
(where
is some distinguished
value outside
).
for all
Invoke a mesh-based packet routing algorithm on the ,
such that each non-
value is routed to its target
node . Each time a value arrives at its target ,
discard it and flip .
After these steps, contain the result of the
multiplication, and the mesh is ready for the next multiplication. As
before, in the inner product computation stage of the Wiedemann
algorithm, we need only compute
for some vector ,
so we load the -th coordinate of into node during
initialization, and compute the single-bit result
inside
the mesh during the next multiplication.
There remains the choice of a routing algorithm. Many candidates exist
(see [7] for a survey). To minimize hardware cost, we restrict
our attention to algorithms for the ``one packet'' model, in which
at each step every node holds at most one packet (and consequentially
each node can send at most one packet and receive at most one packet
per step). Note that this rules out most known algorithms, including
those for the well-studied ``hot-potato'' routing model which provides
a register for every edge.
Since we do binary multiplication, the routing problem
has the following unusual property: pairwise packet annihilation is
allowed. That is, pairs of packets with identical values may be ``cancelled
out'' without affecting the result of the computation. This relaxation
can greatly reduce the congestion caused by multiple packets converging
to a common destination. Indeed this
seems to render commonly-cited lower bounds inapplicable, and we are
not aware of any discussion of this variant in the literature. While
known routing and sorting algorithms can be adapted to our task, we
suggest a new routing algorithm that seems optimal, based on our
empirical tests.
The algorithm, which we call clockwise transposition routing,
has an exceptionally simple control structure which consists of
repeating 4 steps. Each step involves compare-exchange operations on
pairs of neighboring nodes, such that the exchange is performed iff it
reduces the distance-to-target of the non-
value (out of at
most 2) that is farthest from its target along the relevant direction.
This boils down to comparison of the target row indices (for vertically
adjacent nodes) or target column indices (for horizontally adjacent
nodes). For instance, for horizontally adjacent nodes such
that resides on column and
resides on
column , an exchange of and will be done iff
. To this we add annihilation: if
then
both are replaced by
.
The first step of clockwise transposition routing consists of
compare-exchange between each node residing on an odd row with
the node above it (if any). The second step consists of
compare-exchange between each node residing on an odd column
with the node to its right (if any). The third and fourth steps
are similar to the first and second respectively, except that they
involve the neighbors in the opposite direction. It is easily
seen that each node simply performs compare-exchanges with its
four neighbors in either clockwise or counterclockwise order.
We do not yet have a theoretical analysis of this algorithm. However, we
have
simulated it on numerous inputs of sizes up to
with
random inputs drawn from a distribution mimicking that of the above
mesh, as well as the simple distribution that puts a random value
in every node. In all runs (except for very small meshes), we have
not observed even a single case where the running time exceeded
steps. This is just two steps from the trivial lower bound .
Our algorithm is a generalization of odd-even transposition sort, with
a schedule that is identical to the ``2D-bubblesort'' algorithm of
[8] but with different compare-exchange elements. The
change from sorting to routing is indeed quite beneficial, as
[8] shows that 2D-bubblesort is considerably slower than
the observed performance of our clockwise transposition routing. The
new algorithm appears to be much faster than the sorting
algorithm (due to Schimmler) used in [1], and its local control
is very simple compared to the complicated recursive algorithms that
achieve the -step lower bound on mesh sorting
(cf. [16]).
A physical realization of the mesh will contain many local faults
(especially for devices that are wafer-scale or larger, as discussed
below). In the routing-based mesh, we can handle local defects by
algorithmic means as follows. Each node shall contain 4 additional
state bits, indicating whether each of its 4 neighbors is
``disabled''. These bits are loaded during device initialization,
after mapping out the defects. The compare-exchange logic is augmented
such that if node has a ``disabled'' neighbor in direction
then never performs an exchange in that direction, but
always performs the exchange in the two directions orthogonal to
. This allows us to ``close off'' arbitrary rectangular
regions of the mesh, such that values that reach a ``closed-off''
region from outside are routed along its perimeter. We add a few spare
nodes to the mesh, and manipulate the mesh inputs such that the spare
effectively replace the nodes of the in closed-off regions. We
conjecture that the local disturbance caused by a few small closed-off
regions will not have a significant effect on the routing performance.
Going back to the cost evaluation, we see that replacing the
sorting-based mesh with a routing-based mesh reduces time by a factor
of
. Also, note that the values are used
just once per multiplication, and can thus be stored in slower DRAM
cells in the vicinity of the node. DRAM cells are much smaller than
edge-triggered flip-flops, since they require only one transistor and
one capacitor per bit. Moreover, the regular structure of DRAM banks
allows for very dense packing. Using large banks of embedded DRAM
(which are shared by many nodes in their vicinity), the amortized chip
area per DRAM bit is about
. Our
Northwood-based estimates lead to
per
transistor, so we surmise that for our purposes a DRAM bit costs
as much as a logic transistor, or about as much as a
flip-flop. For simplicity, we ignore the circuitry needed to retrieve
the values from DRAM -- this can be done cheaply by temporarily
wiring chains of adjacent into shift registers. In terms of
circuit size, we effectively eliminate two of the three large
registers per node, and some associated logic, so the routing-based
mesh is about 3 times cheaper to manufacture. Overall, we gain a
reduction of a factor
in the throughput cost.
5.5. An improved routing-based circuit.
We now tweak the routing-based circuit design to gain additional cost
reductions. Compared to the sorting-based design
(cf. 5.3), these will yield a (constant-factor)
improvement by several order of magnitudes. While asymptotically
insignificant, this suggests a very practical device for the NFS
matrix step of 1024-bit moduli. Moreover, it shows that already
for 1024-bit moduli, the cost of parallelization can be negligible
compared to the cost of the RAM needed to store the input, and thus
the speed advantage is gained essentially for free.
The first improvement follows from increasing the density of
targets. Let denote the average number of registers
per node. In the above scheme,
. The total
number of registers is fixed at , so if we increase
the number of mesh nodes decreases by . However, we no
longer have enough mesh nodes to route all the nonzero entries of
simultaneously. We address this by partially serializing the routing
process, as follows. Instead of storing one matrix entry
per node, we store such values per node: for
,
each node is ``in charge'' of a set of matrix columns
, in the sense that node
contains the registers
, and the
nonzero elements of in columns
. To
carry out a multiplication we perform iterations, where each
iteration consists of retrieving the next such nonzero element (or
skipping it, depending on the result of the previous multiplication)
and then performing clockwise transposition routing as before.
The second improvement follows from using block Wiedemann with a
blocking factor (cf. 2.5). Besides reducing the
number of multiplications by a factor of roughly
(cf. 5.3), this produces an opportunity for reducing
the cost of multiplication, as follows. Recall that in block
Wiedemann, we need to perform multiplication chains of the form
, for
and
, and later again,
for
. The idea is to perform several chains in
parallel on a single mesh, reusing most resources (in particular, the
storage taken by ). For simplicity, we will consider handling all
chains on one mesh. In the routing-based circuits described so
far, each node emitted at most one message per routing operation -- a
matrix row index, which implies the address of the target cell. The
information content of this message (or its absence) is a single
bit. Consider attaching bits of information to this message:
bits for the row index, and bits of ``payload'', one
bit per multiplication chain.
Combining the two generalizations gives the following algorithm, for
and integer . The case requires
distributing the entries of each matrix column among several mesh
nodes, as in 5.4, but its cost is similar.
Let
be a partition of
,
. Each node
contains single-bit registers and
for all
and , and a register
of size
. Node also contains a list
of the nonzero matrix entries in the columns
of , and an index into . Initially, load the
vectors into the
registers. Each multiplication
is then performed thus:
For all and ,
. For all ,
.
Repeat times:
For all :
,
,
.
Invoke the clockwise transposition routing algorithm on the
, such that each value
is
routed to the node for which .
During routing,
whenever a node receives a message
such that , it sets
for
and
discards the message. Moreover, whenever packets
and
in adjacent nodes are compared,
they are combined: one is annihilated and the other is replaced by
.
for all and .
After these steps,
contain the bits of
and the
mesh is ready for the next multiplication. We need to compute and
output the inner products
for some vectors
, and this computation should be completed before
the next multiplication is done. In general, this seems to require
additional wires between neighboring mesh nodes and
additional registers. However, usually the are chosen to have
weight 1 or 2, so the cost of computing these inner products can be
kept very low. Also, note that the number of routed messages is now
doubled, because previously only half the nodes sent non-
messages. However, empirically it appears that the clockwise
transposition routing algorithm handles the full load without any
slowdown.
It remains to determine the optimal values of and . This
involves implementation details and technological quirks, and
obtaining precise figures appears rather hard. We thus derive
expressions for the various cost measures, based on parameters which
can characterize a wide range of implementations. We then substitute
values that reasonably represent today's technology, and optimize for
these. The parameters are as follows:
Let , and be the average wafer area
occupied by a logic transistor, an edge-triggered flip-flop and a DRAM
bit, respectively (including the related wires).
Let be the area of a wafer.
Let be the wafer area occupied by an inter-wafer
connection pad (cf. 5.3).
Let
be the construction cost of a single wafer (in large
quantities).
Let
be the cost of a DRAM bit that is stored off the
wafers (this is relevant only to the FPGA design of
Appendix A).
Let
be the reciprocal of the memory DRAM access
bandwidth of a single wafer (relevant only to FPGA).
Let
be the time it takes for signals to propagate
through a length of circuitry (averaged over logic, wires, etc.).
Let
be the time it takes to transmit one bit through a
wafer I/O pad.
We consider three concrete implementations: custom-produced ``logic''
wafers (as used in 5.3, with which we maintain
consistency), custom-produced ``DRAM'' wafers (which reduce the size
of DRAM cells at the expense of size and speed of logic transistors)
and an FPGA-based design using off-the-shelf parts
(cf. Appendix A). Rough estimates of the respective
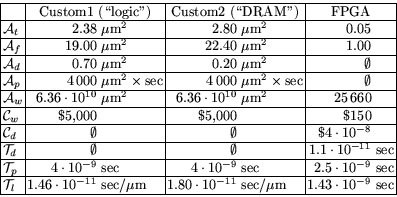
parameters are given in Table 2.
Table 2:
Implementation hardware parameters
marks values that are inapplicable, and taken to be zero.
The cost of the matrix step is derived with some additional
approximations:
The number of mesh nodes is .
The values in
(i.e., the nonzero entries of ) can
be stored in DRAM banks in the vicinity of the nodes, where (with an
efficient representation) they occupy
per node.
The registers can be moved to DRAM banks, where they
occupy
per node.
The registers can also be moved to DRAM. However, to
update the DRAM when a message is received we need additional
storage. Throughout the steps of a routing operation, each
node gets 1 message on average (or less, due to annihilation). Thus
latch bits per node would suffice (if they are still
in use when another message arrives, it can be forwarded to another
node and handled when it arrives again). This occupies
per node when , and
per
node when .
The bitwise logic related to the registers, the
and the last bits of the registers together
occupy
per node.
The registers occupy
per node
The rest of the mesh circuitry (clock distribution, DRAM access,
clockwise transposition routing, I/O handling, inner products, etc.)
occupies
per node.
Let be total area of a mesh node, obtained by summing the
above (we get different formulas for vs. ).
Let
be the total area of the mesh nodes
(excluding inter-wafer connections).
Let
be the number of wafers required to implement the
matrix step, and let
be the number of inter-wafer connection
pads per wafer. For single-wafer designs,
and
. For multiple-wafer
designs, these values are derived from equations for wafer area and
bandwidth:
.
Let
be total number of DRAM bits (obtained by evaluating
for
).
Let
be the number of DRAM bit accesses (reads+writes)
performed throughout the matrix step. We get:
, where the first term due to the the updates
and the second term accounts for reading the matrix entries.
Let
be the total construction
cost for the matrix step.
The full block Wiedemann algorithm consists of
matrix-by-vector multiplications, each of which consists of
routing operations, each of which consists of
clocks. Each clock cycle takes
.
Let
be the time taken by the full block Wiedemann
algorithm. We get:
.
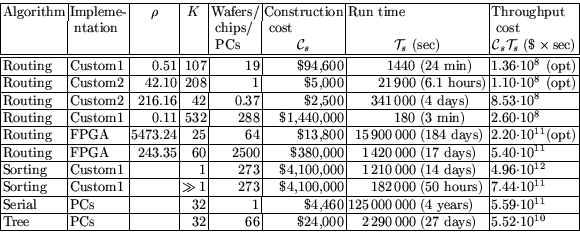
Table 3 lists the cost of the improved
routing-based circuit for several choices of and , according
to the above. It also lists the cost of the sorting-based circuits
(cf. 5.3) and the PC implementation of
Appendix B. The lines marked by ``(opt)'' give the
parameter choice that minimize the throughput cost for each type of
hardware.
The second line describes a routing-based design whose throughput cost
is roughly times lower than that of the original
sorting-based circuit (or times lower than sorting with
). Notably, this is a single-wafer device, which completely
solves the technological problem of connecting multiple wafers with
millions of parallel wires, as necessary in the original design of
[1]. The third line shows that significant parallelism can be
gained essentially for free: here, 88% of the wafer area is occupied
simply by the DRAM banks needed to store the input matrix, so further
reduction in construction cost seems impossible.
Table 3:
Cost of the matrix step for the ``small'' matrix
5.6. An improved circuit for the ``large'' matrix.
The large matrix resulting from ordinary relation collection contains
times more columns:
. We assume that the
average column density remains . It is no longer possible to
fit the device on a single wafer, so the feasibility of the mesh
design now depends critically on the ability to make high bandwidth
inter-wafer connections (cf. 5.3).
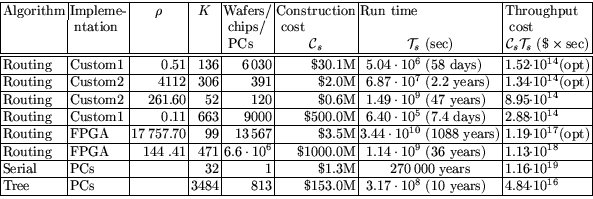
Using the formulas given in the previous section, we obtain the costs
in Table 4 for the custom and FPGA
implementations, for various parameter choices. The third line shows
that here too, significant parallelism can be attained at very little
cost (88% of the wafer area is occupied by DRAM storing the
input). As can be seen, the improved mesh is quite feasible also for
the large matrix, and its cost is a small fraction of the cost of the
alternatives, and of relation collection.
Table 4:
Cost of the matrix step for the ``large'' matrix
5.7. Summary of hardware findings.
The improved design of 5.5 and 5.6,
when implemented using custom hardware, appears feasible for both
matrix sizes. Moreover, it is very attractive when compared to the
traditional serial implementations (though appropriate parallelization
techniques partially close this gap; see Appendix B).
However, these conclusions are based on numerous assumptions, some
quite optimistic. Much more research, and possibly actual relation
collection experiments, would have to be carried out to get a clearer
grasp of the actual cost (time and money) of both the relation
collection and matrix steps for 1024-bit moduli.
In light of the above, one may try to improve the overall performance
of NFS by re-balancing the relation collection step and the matrix
step, i.e., by increasing the smoothness bounds (the opposite of the
approach sketched in Remark 3.7). For ordinary NFS,
asymptotically this is impossible since the parameters used for
ordinary relation collection (i.e., the ``large'' matrix) already
minimize the cost of relation collection (cf. 2.6). For
improved NFS that is applied to a single factorization
(cf. 2.7), if we disregard the cost of the matrix step
and optimize just for relation collection then we can expect
a cost reduction of about
.
If many integers in a large range must be factored -- a reasonable
assumption given our interpretation of the throughput cost
(cf. 3.2) -- a much faster method exists
(cf. [4]). It remains to be studied whether these asymptotic
properties indeed hold for 1024-bit moduli and what are the practical
implications of the methods from [4].
Next:Conclusion Up:Analysis of Bernstein's Factorization Previous:Operation count, equipment cost,
![$\displaystyle 6 700 000\cdot\frac{L_{2^{1024}}[1/3,2/3^{2/3}]}{L_{2^{512}}[1/3,2/3^{2/3}]}\approx1.8\cdot10^{10}$](img250.png)
![$\displaystyle 1.8\cdot10^{10}\cdot\frac{L_{2^{1024}}[1/3,(5/3)^{1/3}(2/3)]}{L_{2^{1024}}[1/3,2/3^{2/3}]}\approx8.7\cdot10^7.$](img254.png)
![$\displaystyle 8\cdot\frac{L_{2^{1024}}[1/3,4/3^{2/3}]}{L_{2^{512}}[1/3,4/3^{2/3}]}\approx6\cdot10^7$](img256.png)
![$\displaystyle \frac{L_{2^{1024}}[1/3,(5/3)^{4/3}]}{L_{2^{1024}}[1/3,4/3^{2/3}]}\approx5$](img257.png)