
Up: Analysis of Bernstein's Factorization
Previous: Using off-the-shelf hardware for
Subsections
The traditional approach to the matrix step
We give a rough estimate of the price and performance of a traditional
implementation of the matrix step using the block Lanczos
method [13] running on standard PC hardware. Let the
``small'' and ``large'' matrices be as in 5.1.
B..1. Processing the ``small'' matrix using PCs.
A bare-bones PC with a 2GHz Pentium 4 CPU can be bought for
$300, plus $320 per gigabyte of RAM. We will use block Lanczos with
a blocking factor of 32, to match the processor word size. The
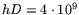 nonzero entries of the ``small'' matrix require 13GB
of storage, and the auxiliary
nonzero entries of the ``small'' matrix require 13GB
of storage, and the auxiliary 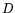 -dimensional vectors require under
1GB. The construction cost is thus about $4,500.
The bandwidth of the fastest PC memory is 4.2GB/sec. In each
matrix-by-vector multiplication, all the nonzero matrix entries
are read, and each of these causes an update (read and write) of a
32-bit word. Thus, a full multiplication consists of accessing
-dimensional vectors require under
1GB. The construction cost is thus about $4,500.
The bandwidth of the fastest PC memory is 4.2GB/sec. In each
matrix-by-vector multiplication, all the nonzero matrix entries
are read, and each of these causes an update (read and write) of a
32-bit word. Thus, a full multiplication consists of accessing
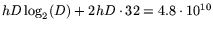 bits, which takes about 11
seconds. The effect of the memory latency on non-sequential access,
typically 40n, raises this to about 50 seconds (some reduction may be
possible by optimizing the memory access pattern to the specific DRAM
modules used, but this appears nontrivial). Since
bits, which takes about 11
seconds. The effect of the memory latency on non-sequential access,
typically 40n, raises this to about 50 seconds (some reduction may be
possible by optimizing the memory access pattern to the specific DRAM
modules used, but this appears nontrivial). Since 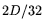 matrix-by-vector multiplications have to be carried out [13],
we arrive at a total of
matrix-by-vector multiplications have to be carried out [13],
we arrive at a total of
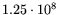 seconds (disregarding the
cheaper inner products), i.e., about 4 years.
The throughput cost is
seconds (disregarding the
cheaper inner products), i.e., about 4 years.
The throughput cost is
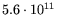 , which is somewhat better
than the sorting-based mesh design (despite the asymptotic advantage
of the latter), but over 5000 times worse than the the single-wafer
improved mesh design (cf. 5.5). Parallelization can be
achieved by increasing the blocking factor of the Lanczos algorithm
-- this would allow for different tradeoffs between construction cost
and running time, but would not decrease the throughput cost.
, which is somewhat better
than the sorting-based mesh design (despite the asymptotic advantage
of the latter), but over 5000 times worse than the the single-wafer
improved mesh design (cf. 5.5). Parallelization can be
achieved by increasing the blocking factor of the Lanczos algorithm
-- this would allow for different tradeoffs between construction cost
and running time, but would not decrease the throughput cost.
B..2. Processing the ``large'' matrix using PCs.
The large matrix contains 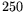 times more columns at the same
(assumed) average density. Thus, it requires 250 times more memory and
times more columns at the same
(assumed) average density. Thus, it requires 250 times more memory and
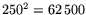 times more time than the small matrix. Moreover, all
row indices now occupy
times more time than the small matrix. Moreover, all
row indices now occupy
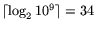 bits instead of
just 24. The cost of memory needed to store the matrix is $1.36M (we
ignore the lack of support for this amount of memory in existing
memory controllers), and the running time is
bits instead of
just 24. The cost of memory needed to store the matrix is $1.36M (we
ignore the lack of support for this amount of memory in existing
memory controllers), and the running time is 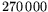 years. This
appears quite impractical (we cannot increase the blocking factor by
over
years. This
appears quite impractical (we cannot increase the blocking factor by
over 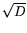 , and even if we could, the construction cost would be
billions of dollars).
, and even if we could, the construction cost would be
billions of dollars).
Remark B..3
Once attention is drawn to the cost of memory, it becomes evident that
better schemes are available for parallelizing a PC-based
implementation. One simple scheme involves distributing the matrix
columns among numerous PCs such that each node 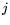 is in charge of
some set of columns
is in charge of
some set of columns
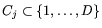 , and contains only
these matrix entries (rather than the whole matrix). The nodes are
networked together with a binary tree topology. Let
, and contains only
these matrix entries (rather than the whole matrix). The nodes are
networked together with a binary tree topology. Let 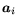 denote
the
denote
the 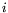 -th column of
-th column of 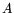 . Each matrix-by-vector multiplication
. Each matrix-by-vector multiplication
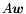 consists of the root node broadcasting the bits
consists of the root node broadcasting the bits
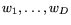 down the tree, each node computing a partial sum
vector
down the tree, each node computing a partial sum
vector
 , and finally
performing a converge-cast operation to produce the sum
, and finally
performing a converge-cast operation to produce the sum
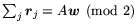 at the root. If the broadcast and
converge-cast are done in a pipelined manner on 0.5 gigabit links,
this is easily seen to reduce the throughput cost to roughly
at the root. If the broadcast and
converge-cast are done in a pipelined manner on 0.5 gigabit links,
this is easily seen to reduce the throughput cost to roughly
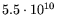 for the small matrix and
for the small matrix and
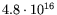 for the
large matrix (see
Tables 3,4).
For constant-bandwidth links, this scheme is asymptotically
inefficient since its throughput cost is
for the
large matrix (see
Tables 3,4).
For constant-bandwidth links, this scheme is asymptotically
inefficient since its throughput cost is 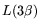 . However, for the
parameters considered it is outperformed only by the custom-built
improved mesh.
. However, for the
parameters considered it is outperformed only by the custom-built
improved mesh.
Up: Analysis of Bernstein's Factorization
Previous: Using off-the-shelf hardware for