

Next: Operation count, equipment cost,
Up: Analysis of Bernstein's Factorization
Previous: Background on the number
Subsections
The circuits for integer factorization from [1]
3.1. Matrix-by-vector multiplication using mesh sorting.
In [1] an interesting new mesh-sorting-based method is described
to compute a matrix-by-vector product. Let 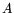 be the bit matrix from 2.5 with
be the bit matrix from 2.5 with
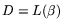 columns
and weight
columns
and weight
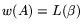 , and let
, and let 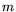 be the least power of
be the least power of 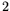 such
that
such
that
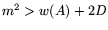 . Thus
. Thus
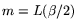 . We assume, without loss of
generality, that is square. A mesh of
. We assume, without loss of
generality, that is square. A mesh of 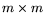 processors, each with
processors, each with
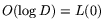 memory, initially stores the
matrix and a not necessarily sparse
memory, initially stores the
matrix and a not necessarily sparse 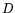 -dimensional bit vector
-dimensional bit vector 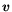 .
An elegant method is given that computes the product
.
An elegant method is given that computes the product 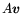 using repeated sorting in
using repeated sorting in 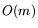 steps,
where each step involves a small constant number of simultaneous operations
on all mesh processors. At the end of the computation can
easily be extracted from the mesh. Furthermore, the mesh is immediately,
without further changes to its state, ready for the computation of the
product of and the vector . We use ``circuit-NFS'' to refer to NFS
that uses the mesh-sorting-based matrix step.
steps,
where each step involves a small constant number of simultaneous operations
on all mesh processors. At the end of the computation can
easily be extracted from the mesh. Furthermore, the mesh is immediately,
without further changes to its state, ready for the computation of the
product of and the vector . We use ``circuit-NFS'' to refer to NFS
that uses the mesh-sorting-based matrix step.
3.2. The throughput cost function from [1].
Judging by operation counts, the mesh-based algorithm is not competitive
with
the traditional way of computing : as indicated in 2.5 it
can be done in
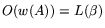 operations. The mesh-based computation
takes
steps on all mesh processors simultaneously, resulting in
an operation count per matrix-by-vector multiplication of
operations. The mesh-based computation
takes
steps on all mesh processors simultaneously, resulting in
an operation count per matrix-by-vector multiplication of
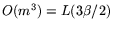 .
Iterating the matrix-by-vector multiplications
.
Iterating the matrix-by-vector multiplications 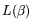 times results
in a mesh-sorting-based matrix step that requires
times results
in a mesh-sorting-based matrix step that requires
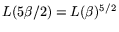 operations as opposed to just
operations as opposed to just 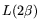 for the traditional approach.
This explains the non-ordinary relation collection parameters used
in [1] corresponding to the analysis given in 2.6 for
for the traditional approach.
This explains the non-ordinary relation collection parameters used
in [1] corresponding to the analysis given in 2.6 for
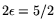 , something we comment upon below in 3.3.
However, the standard comparison of operation counts overlooks the
following fact.
The traditional approach
requires memory
, something we comment upon below in 3.3.
However, the standard comparison of operation counts overlooks the
following fact.
The traditional approach
requires memory
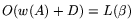 for storage of and the vector;
given
that amount of memory it takes time . But given the
mesh, with
for storage of and the vector;
given
that amount of memory it takes time . But given the
mesh, with
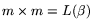 , the mesh-based approach takes time just
, the mesh-based approach takes time just
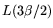 because during each unit of time operations are
carried out simultaneously on the mesh. To capture the advantage of ``active
small processors'' (as in the mesh) compared to ``inactive memory''
(as in the traditional approach) and the fact that their price
is comparable, it is stipulated in [1] that the cost of factorization
is ``the product of the time and the cost of the machine.'' We refer to
this cost function as throughput cost,
since it can be interpreted as measuring the equipment cost per unit
problem-solving throughput.
It is frequently used in VLSI design (where it's known as ``AT cost'',
for Area
because during each unit of time operations are
carried out simultaneously on the mesh. To capture the advantage of ``active
small processors'' (as in the mesh) compared to ``inactive memory''
(as in the traditional approach) and the fact that their price
is comparable, it is stipulated in [1] that the cost of factorization
is ``the product of the time and the cost of the machine.'' We refer to
this cost function as throughput cost,
since it can be interpreted as measuring the equipment cost per unit
problem-solving throughput.
It is frequently used in VLSI design (where it's known as ``AT cost'',
for Area Time), but apparently was not used previously in the
context of computational number theory.
It appears that throughput cost is indeed appropriate when a large number of
problems must be solved during some long period of time while minimizing
total expenses. This does not imply that throughput cost is
always appropriate for assessing security, as illustrated by the
following example. Suppose Carrol wishes to assess the
risk of her encryption key being broken by each of two adversaries,
Alice and Bob. Carrol knows that Alice has plans for a device
that costs $1M and takes 50 years to break a key, and
that Bob's device costs $50M and takes 1 year
to break a key. In one scenario, each adversary has a
$1M budget -- clearly Alice is dangerous and Bob is
not. In another scenario, each adversary has a $50M budget.
This time both are dangerous, but Bob apparently forms a greater
menace because he can break Carrol's key within one year, while Alice
still needs 50 years. Thus, the two devices have the same throughput
cost, yet either can be more ``dangerous'' than the other, depending on
external settings. The key point is that if Alice and Bob have many
keys to break within 50 years then indeed their cost-per-key figures
are identical, but the time it will take Bob to break Carrol's key
depends on her priority in his list of victims, and arguably Carrol
should make the paranoid assumption that she is first.
In Section 4 we comment further on
performance measurement for the NFS.
Time), but apparently was not used previously in the
context of computational number theory.
It appears that throughput cost is indeed appropriate when a large number of
problems must be solved during some long period of time while minimizing
total expenses. This does not imply that throughput cost is
always appropriate for assessing security, as illustrated by the
following example. Suppose Carrol wishes to assess the
risk of her encryption key being broken by each of two adversaries,
Alice and Bob. Carrol knows that Alice has plans for a device
that costs $1M and takes 50 years to break a key, and
that Bob's device costs $50M and takes 1 year
to break a key. In one scenario, each adversary has a
$1M budget -- clearly Alice is dangerous and Bob is
not. In another scenario, each adversary has a $50M budget.
This time both are dangerous, but Bob apparently forms a greater
menace because he can break Carrol's key within one year, while Alice
still needs 50 years. Thus, the two devices have the same throughput
cost, yet either can be more ``dangerous'' than the other, depending on
external settings. The key point is that if Alice and Bob have many
keys to break within 50 years then indeed their cost-per-key figures
are identical, but the time it will take Bob to break Carrol's key
depends on her priority in his list of victims, and arguably Carrol
should make the paranoid assumption that she is first.
In Section 4 we comment further on
performance measurement for the NFS.
3.3. Application of the throughput cost.
The time required for all matrix-by-vector multiplications on the mesh is
. The equipment cost of the mesh is the cost of 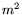 small processors with
small processors with 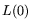 memory per processor, and is thus .
The throughput cost, the product of the time and the cost of the
equipment, is therefore
memory per processor, and is thus .
The throughput cost, the product of the time and the cost of the
equipment, is therefore
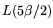 . The matrix step of standard-NFS
requires time and equipment cost for the memory,
resulting in a throughput cost of
. The matrix step of standard-NFS
requires time and equipment cost for the memory,
resulting in a throughput cost of 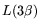 . Thus, the throughput
cost advantage of the mesh-based approach is a factor
. Thus, the throughput
cost advantage of the mesh-based approach is a factor
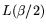 if the two methods would use the same
if the two methods would use the same 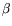 (cf. Remark 3.4).
The same observation applies if the standard-NFS matrix step is
(cf. Remark 3.4).
The same observation applies if the standard-NFS matrix step is 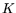 -fold
parallelized, for reasonable (cf. 2.5): the time drops
by a factor which is cancelled (in the
throughput cost) by a times higher equipment cost because each
participating processor needs the same memory . In circuit-NFS
(i.e., the mesh) a parallelization factor is used: the time
drops by a factor only (not ), but the equipment cost
stays the same because memory suffices for each of the
participating processors. Thus, with the throughput cost circuit-NFS
achieves an advantage of
. The mesh itself can of course be
-fold parallelized but the resulting -fold increase in equipment
cost and -fold drop in time cancel each other in the throughput
cost [1, Section 4].
-fold
parallelized, for reasonable (cf. 2.5): the time drops
by a factor which is cancelled (in the
throughput cost) by a times higher equipment cost because each
participating processor needs the same memory . In circuit-NFS
(i.e., the mesh) a parallelization factor is used: the time
drops by a factor only (not ), but the equipment cost
stays the same because memory suffices for each of the
participating processors. Thus, with the throughput cost circuit-NFS
achieves an advantage of
. The mesh itself can of course be
-fold parallelized but the resulting -fold increase in equipment
cost and -fold drop in time cancel each other in the throughput
cost [1, Section 4].
Remark 3.4
It can be argued that before evaluating an existing algorithm based on a new
cost function, the algorithm first should be tuned to the new cost function.
This is further commented upon below in 3.5.
3.5. Implication of the throughput cost.
We consider the implication of the matrix step
throughput cost of
for
circuit-NFS compared to for standard-NFS.
In [1] the well known fact is used that the throughput cost
of relation collection is
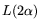 (cf. 2.4): an
operation
count of
on a single processor with memory results
in time
, equipment cost , and throughput cost
. This can be time-sliced in any way that is convenient, i.e.,
for any use processors of memory each and spend time
(cf. 2.4): an
operation
count of
on a single processor with memory results
in time
, equipment cost , and throughput cost
. This can be time-sliced in any way that is convenient, i.e.,
for any use processors of memory each and spend time
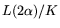 on all processors simultaneously, resulting in the same
throughput cost
. Thus, for relation collection the
throughput cost is proportional to the operation count.
The analysis of 2.6 applies with
and leads to an optimal overall circuit-NFS throughput cost
of
on all processors simultaneously, resulting in the same
throughput cost
. Thus, for relation collection the
throughput cost is proportional to the operation count.
The analysis of 2.6 applies with
and leads to an optimal overall circuit-NFS throughput cost
of
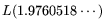 . As mentioned above and in 3.2, the
throughput cost and the operation count are equivalent for
both relation collection and the matrix step of circuit-NFS.
Thus, as calculated in 2.6, circuit-NFS is
from an operation count point of view less powerful than standard-NFS,
losing already 40 bits in the 500-bit range (disregarding the
. As mentioned above and in 3.2, the
throughput cost and the operation count are equivalent for
both relation collection and the matrix step of circuit-NFS.
Thus, as calculated in 2.6, circuit-NFS is
from an operation count point of view less powerful than standard-NFS,
losing already 40 bits in the 500-bit range (disregarding the 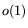 's)
when compared to standard-NFS with ordinary parameter choices.
This conclusion applies to any NFS implementation, such as many existing
ones, where memory requirements are not multiplicatively included in the
cost function.
But operation count is not the point of view taken in [1]. There
standard-NFS is compared to circuit-NFS in the following way. The parameters
for standard-NFS are chosen under the assumption that the throughput
cost
of relation collection is
's)
when compared to standard-NFS with ordinary parameter choices.
This conclusion applies to any NFS implementation, such as many existing
ones, where memory requirements are not multiplicatively included in the
cost function.
But operation count is not the point of view taken in [1]. There
standard-NFS is compared to circuit-NFS in the following way. The parameters
for standard-NFS are chosen under the assumption that the throughput
cost
of relation collection is
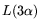 : operation count
and
memory cost
: operation count
and
memory cost 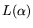 for the sieving result in time
and equipment cost
for the sieving result in time
and equipment cost
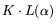 (for any -fold
parallelization) and thus throughput cost
. This disregards
the fact that long before [1] appeared is was known that the use
of memory per processor may be convenient, in practice and for
relatively small numbers, but is by no means required
(cf. 2.4).
In any case, combined with for the throughput cost of the
matrix step this leads to
(for any -fold
parallelization) and thus throughput cost
. This disregards
the fact that long before [1] appeared is was known that the use
of memory per processor may be convenient, in practice and for
relatively small numbers, but is by no means required
(cf. 2.4).
In any case, combined with for the throughput cost of the
matrix step this leads to
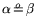 , implying that the analysis
from 2.6 with
, implying that the analysis
from 2.6 with
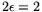 applies, but that the resulting
operation count
must be raised to the
applies, but that the resulting
operation count
must be raised to the 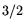 -th power. In [1] the improvement
from [4] mentioned in 2.7 is used, leading to a
throughput cost for standard-NFS of
-th power. In [1] the improvement
from [4] mentioned in 2.7 is used, leading to a
throughput cost for standard-NFS of
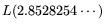 (where
(where
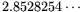 is
is 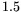 times the
times the
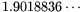 referred to
in 2.7). Since
referred to
in 2.7). Since
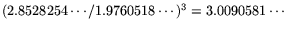 , it is suggested
in [1] that the number of digits of factorable composites
grows by a factor
, it is suggested
in [1] that the number of digits of factorable composites
grows by a factor 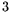 if circuit-NFS is used instead of standard-NFS.
if circuit-NFS is used instead of standard-NFS.
3.6. Alternative interpretation.
How does the comparison between circuit-NFS and standard-NFS with respect to
their throughput costs turn out if standard-NFS is first properly tuned
(Remark 3.4) to the throughput cost function, given the
state of the
art in, say, 1990 (cf. [10, 4.15]; also the year that [4]
originally appeared)? With throughput cost
for relation
collection (cf. above and 2.4), the analysis
from 2.6 with
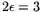 applies, resulting in a
throughput cost of just
applies, resulting in a
throughput cost of just
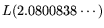 for standard-NFS. Since
for standard-NFS. Since
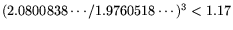 , this would suggest
that
, this would suggest
that 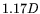 -digit composites can be factored using circuit-NFS for the
throughput cost of -digit integers using standard-NFS. The
significance
of this comparison depends on whether or not the throughput cost is
an acceptable way of measuring the cost of standard-NFS. If not, then the
conclusion based on the operation count (as mentioned above) would be that
circuit-NFS is slower than standard-NFS; but see Section 4 for
a more complete picture. Other examples where it is recognized that the
memory cost of relation collection is asymptotically not a concern can be
found in [12] and [9], and are implied by [14].
-digit composites can be factored using circuit-NFS for the
throughput cost of -digit integers using standard-NFS. The
significance
of this comparison depends on whether or not the throughput cost is
an acceptable way of measuring the cost of standard-NFS. If not, then the
conclusion based on the operation count (as mentioned above) would be that
circuit-NFS is slower than standard-NFS; but see Section 4 for
a more complete picture. Other examples where it is recognized that the
memory cost of relation collection is asymptotically not a concern can be
found in [12] and [9], and are implied by [14].
Remark 3.7
It can be argued that the approach
in 3.6 of replacing the ordinary standard-NFS parameters
by smaller smoothness bounds in order to make the matrix step easier
corresponds to what happens in many actual NFS factorizations. There
it is done not only to make the matrix step less cumbersome at the cost of
somewhat more sieving, but also to make do with available PC memories.
Each contributing PC uses the largest smoothness bounds and sieving
range that fit conveniently and that cause minimal interference with
the PC-owner's real work. Thus, parameters may vary from machine to machine.
This is combined with other memory saving methods such as ``special- 's.''
In any case, if insufficient memory is available for sieving with optimal
ordinary parameters, one does not run out to buy more memory but settles
for slight suboptimality, with the added benefit of an easier matrix step.
See also 4.1.
In [19], Wiener outlines a three-dimensional circuit for the
matrix step, with structure that is optimal in a certain sense (when
considering the cost of internal wiring). This design leads to a
matrix step exponent of
's.''
In any case, if insufficient memory is available for sieving with optimal
ordinary parameters, one does not run out to buy more memory but settles
for slight suboptimality, with the added benefit of an easier matrix step.
See also 4.1.
In [19], Wiener outlines a three-dimensional circuit for the
matrix step, with structure that is optimal in a certain sense (when
considering the cost of internal wiring). This design leads to a
matrix step exponent of
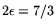 , compared to
, compared to 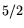 in the designs
of [1] and this paper. However, adaptation of that design to two
dimensions yields a matrix step exponent that is asymptotically
identical to ours, and vice versa. Thus the approach of [19]
is asymptotically equivalent to ours, while its practical cost remains
to be evaluated. We note that in either approach, there are sound
technological reasons to prefer the 2D variant. Interestingly,
is the point where improved and standard NFS become the same
(cf. 2.7).
in the designs
of [1] and this paper. However, adaptation of that design to two
dimensions yields a matrix step exponent that is asymptotically
identical to ours, and vice versa. Thus the approach of [19]
is asymptotically equivalent to ours, while its practical cost remains
to be evaluated. We note that in either approach, there are sound
technological reasons to prefer the 2D variant. Interestingly,
is the point where improved and standard NFS become the same
(cf. 2.7).
Next: Operation count, equipment cost,
Up: Analysis of Bernstein's Factorization
Previous: Background on the number